Fluent Python Study Notes
1. Python 数据模型
1.1 一摞有序的纸牌
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JKQA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in suits
for rank in ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
suit_values = dict(spades=3, hearts=2, diamonds=1, clubs=0)
def spades_high(card):
rank_value = FrenchDeck.ranks.index(card.rank)
return rank_value * len(suit_values) + suit_values[card.suit]
1.2 如何使用特殊方法
from math import hypot
class Vector:
def __init__(self, x=0, y=0):
self.x = x
self.y = y
def __repr__(self):
return 'Vector(%r, %r)' % (self.x, self.y)
def __abs__(self):
return hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
def __add__(self, other):
x = self.x + other.x
y = self.y + other.y
return Vector(x, y)
def __mul__(self, scalar):
return Vector(self.x * scalar, self.y * scalar)
1.3 特殊方法一览
跟运算符无关的特殊方法:
| 类别 | 方法名 |
|---|---|
| 字符串 / 字节序列表示形式 | __repr__、__str__、__format__、__bytes__ |
| 数值转换 | __abs__、__bool__、__complex__、__int__、__float__、__hash__、__index__ |
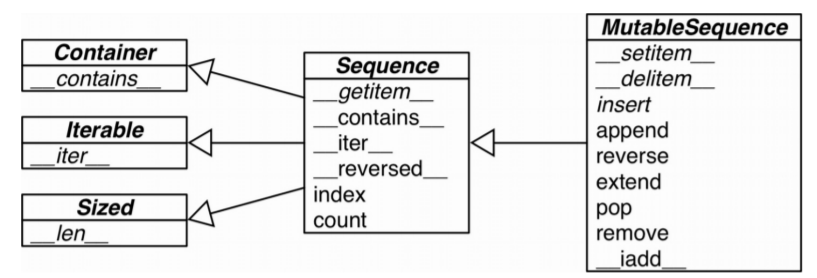
| 集合模拟 | __len__、__getitem__、__setitem__、__delitem__、__contains__ |
| 迭代枚举 | __iter__、__reversed__、__next__ |
| 可调用模拟 | __call__ |
| 上下文管理 | __enter__、__exit__ |
| 实例创建和销毁 | __new__、__init__、__del__ |
| 属性管理 | __getattr__、__getattribute__、__setattr__、__delattr__、__dir__ |
| 属性描述符 | __get__、__set__、__delete__ |
| 跟类相关的服务 | __prepare__、__instancecheck__、__subclasscheck__ |
跟运算符相关的特殊方法:
| 类别 | 方法名和对应的运算符 |
|---|---|
| 一元运算符 | __neg__ -、__pos__ +、__abs__ abs() |
| 众多比较运算符 | __lt__ <、__le__ <=、__eq__ ==、__ne__ !=、__gt__ >、__ge__ >= |
| 算术运算符 | __add__ +、__sub__ -、__mul__ *、__truediv__ /、__floordiv__ //、__mod__ %、__divmod__ divmod()、__pow__ ** 或pow()、__round__ round() |
| 反向算术运算符 | __radd__、__rsub__、__rmul__、__rtruediv__、__rfloordiv__、__rmod__、__rdivmod__、__rpow__ |
| 增量赋值算术运算符 | __iadd__、__isub__、__imul__、__itruediv__、__ifloordiv__、__imod__、__ipow__ |
| 位运算符 | __invert__ ~、__lshift__ <<、__rshift__ >>、__and__ &、__or__ |、__xor__ ^ |
| 反向位运算符 | __rlshift__、__rrshift__、__rand__、__rxor__、__ror__ |
| 增量赋值位运算符 | __ilshift__、__irshift__、__iand__、__ixor__、__ior__ |
2. 序列构成的数组
2.1 内置序列类型概览
-
容器序列:list、tuple 和 collections.deque 这些序列能存放不同类型的数据。
-
扁平序列:str、bytes、bytearray、memoryview 和 array.array,这类序列只能容纳一种类型。
-
可变序列:list、bytearray、array.array、collections.deque 和 memoryview。
-
不可变序列:tuple、str 和 bytes。
2.2 列表推导和生成器表达式
虽然也可以用列表推导来初始化元组、数组或其他序列类型,但是生成器表达式是更好的选择。这是因为生成器表达式背后遵守了迭代器协议,可以逐个地产出元素,而不是先建立一个完整的列表,然后再把这个列表传递到某个构造函数里。这种方式显然能够节省内存。
>>> symbols = '$¢£¥€¤'
>>> beyond_ascii = [ord(s) for s in symbols if ord(s) > 127] # 列表推导
>>> beyond_ascii
[162, 163, 165, 8364, 164]
>>> beyond_ascii = list(filter(lambda c: c > 127, map(ord, symbols))) # filter map
>>> beyond_ascii
[162, 163, 165, 8364, 164]
>>> tuple(ord(symbol) for symbol in symbols) # 生成器表达式
(36, 162, 163, 165, 8364, 164)
>>> import array
>>> array.array('I', (ord(symbol) for symbol in symbols))
array('I', [36, 162, 163, 165, 8364, 164])
2.3 元组不仅仅是不可变的列表
元组其实是对数据的记录:元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。正是这个位置信息给数据赋予了意义。
lax_coordinates = (33.9425, -118.408056)
latitude, longitude = lax_coordinates # 元组拆包
t = (20, 8) # * 运算符把一个可迭代对象拆开作为函数的参数
quotient, remainder = divmod(*t) # (2, 4)
在元组拆包中使用 * 也可以帮助我们把注意力集中在元组的部分元素上:
>>> a, *body, c, d = range(5)
>>> a, body, c, d
(0, [1, 2], 3, 4)
>>> *head, b, c, d = range(5)
>>> head, b, c, d
([0, 1], 2, 3, 4)
嵌套元组拆包:
metro_areas = [
('Tokyo','JP',36.933,(35.689722,139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
print('{:15} | {:^9} | {:^9}'.format('', 'lat.', 'long.'))
fmt = '{:15} | {:9.4f} | {:9.4f}'
for name, cc, pop, (latitude, longitude) in metro_areas:
if longitude <= 0:
print(fmt.format(name, latitude, longitude))
| lat. | long.
Mexico City | 19.4333 | -99.1333
New York-Newark | 40.8086 | -74.0204
Sao Paul | -23.5478 | -46.6358
2.4 具名元组
collections.namedtuple 是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类——这个带名字的类对调试程序有很大帮助。
创建一个具名元组需要两个参数,一个是类名,另一个是类的各个字段的名字。后者可以是由数个字符串组成的可迭代对象,或者是由空格分隔开的字段名组成的字符串。
>>> from collections import namedtuple
>>> City = namedtuple('City', 'name country population coordinates')
>>> tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
>>> tokyo
City(name='Tokyo', country='JP', population=36.933, coordinates=(35.689722,
139.691667))
>>> tokyo.population
36.933
>>> tokyo.coordinates
(35.689722, 139.691667)
>>> tokyo[1]
'JP'
除了从普通元组那里继承来的属性之外,具名元组还有一些自己专有的属性:
_fields属性是一个包含这个类所有字段名称的元组。- 用
_make()通过接受一个可迭代对象来生成这个类的一个实例,它的作用跟 City(*delhi_data) 是一样的。 _asdict()把具名元组以 collections.OrderedDict 的形式返回,我们可以利用它来把元组里的信息友好地呈现出来。
2.5 作为不可变列表的元组
除了跟增减元素相关的方法之外,元组支持列表的其他所有方法。还有一个例外,元组没有 __reversed__ 方法,但是这个方法只是个优化而已,reversed(my_tuple) 这个用法在没有 __reversed__ 的情况下也是合法的。
列表或元组的方法和属性:
| 列表 | 元组 | ||
|---|---|---|---|
| s.__add__(s2) | ✔ | ✔ | s + s2,拼接 |
| s.__iadd__(s2) | ✔ | s += s2,就地拼接 | |
| s.append(e) | ✔ | 在尾部添加一个新元素 | |
| s.clear() | ✔ | 删除所有元素 | |
| s.__contains__(e) | ✔ | ✔ | s 是否包含 e |
| s.copy() | ✔ | 列表的浅复制 | |
| s.count(e) | ✔ | ✔ | e 在 s 中出现的次数 |
| s.__delitem__(p) | ✔ | 把位于 p 的元素删除 | |
| s.extend(it) | ✔ | 把可迭代对象 it 追加给 s | |
| s.__getitem__(p) | ✔ | ✔ | s[p],获取位置 p 的元素 |
| s.__getnewargs__() | ✔ | 在 pickle 中支持更加优化的序列化 | |
| s.index(e) | ✔ | ✔ | 在 s 中找到元素 e 第一次出现的位置 |
| s.insert(p, e) | ✔ | 在位置 p 之前插入元素e | |
| s.__iter__() | ✔ | ✔ | 获取 s 的迭代器 |
| s.__len__() | ✔ | ✔ | len(s),元素的数量 |
| s.__mul__(n) | ✔ | ✔ | s * n,n 个 s 的重复拼接 |
| s.__imul__(n) | ✔ | s *= n,就地重复拼接 | |
| s.__rmul__(n) | ✔ | ✔ | n * s,反向拼接 * |
| s.pop([p]) | ✔ | 删除最后或者是(可选的)位于 p 的元素,并返回它的值 | |
| s.remove(e) | ✔ | 删除 s 中的第一次出现的 e | |
| s.reverse() | ✔ | 就地把 s 的元素倒序排列 | |
| s.__reversed__() | ✔ | 返回 s 的倒序迭代器 | |
| s.__setitem__(p, e) | ✔ | s[p] = e,把元素 e 放在位置p,替代已经在那个位置的元素 | |
| s.sort([key],[reverse]) | ✔ | 就地对 s 中的元素进行排序,可选的参数有键(key)和是否倒序(reverse) |
2.6 切片
在切片和区间操作里不包含区间范围的最后一个元素是 Python 的风格,这个习惯符合Python、C 和其他语言里以 0 作为起始下标的传统。
s[a:b:c]: 对 s 在 a 和 b 之间以 c 为间隔取值。c 的值还可以为负,负值意味着反向取值。
切片赋值:如果赋值的对象是一个切片,那么赋值语句的右侧必须是个可迭代对象。即便只有单独一个值,也要把它转换成可迭代的序列。
>>> l = list(range(10))
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> l[2:5] = [20, 30]
>>> l
[0, 1, 20, 30, 5, 6, 7, 8, 9]
>>> del l[5:7]
>>> l
[0, 1, 20, 30, 5, 8, 9]
>>> l[3::2] = [11, 22]
>>> l
[0, 1, 20, 11, 5, 22, 9]
- Python Tutor(http://www.pythontutor.com)是一个对 Python 运行原理进行可视化分析的工具。
2.7 list.sort 方法和内置函数 sorted
list.sort 方法会就地排序列表,也就是说不会把原列表复制一份。这也是这个方法的返回值是 None 的原因,提醒你本方法不会新建一个列表。在这种情况下返回 None 其实
是 Python 的一个惯例:如果一个函数或者方法对对象进行的是就地改动,那它就应该返回 None,好让调用者知道传入的参数发生了变动,而且并未产生新的对象。例如,random.shuffle 函数也遵守了这个惯例。
与 list.sort 相反的是内置函数 sorted,它会新建一个列表作为返回值。这个方法可以接受任何形式的可迭代对象作为参数,甚至包括不可变序列或生成器(见第 14 章)。而不管 sorted 接受的是怎样的参数,它最后都会返回一个列表。
不管是 list.sort 方法还是 sorted 函数,都有两个可选的关键字参数。
-
reverse
如果被设定为 True,被排序的序列里的元素会以降序输出(也就是说把最大值当作最小值来排序)。这个参数的默认值是 False。
-
key
一个只有一个参数的函数,这个函数会被用在序列里的每一个元素上,所产生的结果将是排序算法依赖的对比关键字。比如说,在对一些字符串排序时,可以用 key=str.lower 来实现忽略大小写的排序,或者是用 key=len 进行基于字符串长度的排序。这个参数的默认值是恒等函数(identity function),也就是默认用元素自己的值来排序。
2.8 用 bisect 来管理已排序的序列
bisect 模块包含两个主要函数,bisect 和 insort,两个函数都利用二分查找算法来在有序序列中查找或插入元素。
bisect(haystack, needle) 在 haystack(干草垛)里搜索 needle(针)的位置,该位置满足的条件是,把 needle 插入这个位置之后,haystack 还能保持升序。也就是在
说这个函数返回的位置前面的值,都小于或等于 needle 的值。其中 haystack 必须是一个有序的序列。你可以先用 bisect(haystack, needle) 查找位置 index,再用 haystack.insert(index, needle) 来插入新值。但你也可用 insort 来一步到位,并且后者的速度更快一些。
import bisect
import sys
HAYSTACK = [1, 4, 5, 6, 8, 12, 15, 20, 21, 23, 23, 26, 29, 30]
NEEDLES = [0, 1, 2, 5, 8, 10, 22, 23, 29, 30, 31]
ROW_FMT = '{0:2d} @ {1:2d} {2}{0:<2d}'
def demo(bisect_fn):
for needle in reversed(NEEDLES):
position = bisect_fn(HAYSTACK, needle)
offset = position * ' |'
print(ROW_FMT.format(needle, position, offset))
if __name__ == '__main__':
if sys.argv[-1] == 'left':
bisect_fn = bisect.bisect_left
else:
bisect_fn = bisect.bisect
print('DEMO:', bisect_fn.__name__)
print('haystack ->', ' '.join('%2d' % n for n in HAYSTACK))
demo(bisect_fn)
DEMO: bisect_right
haystack -> 1 4 5 6 8 12 15 20 21 23 23 26 29 30
31 @ 14 | | | | | | | | | | | | | |31
30 @ 14 | | | | | | | | | | | | | |30
29 @ 13 | | | | | | | | | | | | |29
23 @ 11 | | | | | | | | | | |23
22 @ 9 | | | | | | | | |22
10 @ 5 | | | | |10
8 @ 5 | | | | |8
5 @ 3 | | |5
2 @ 1 |2
1 @ 1 |1
0 @ 0 0
根据一个分数找出对应的成绩:
>>> def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'):
... i = bisect.bisect(breakpoints, score)
... return grades[i]
...
>>> [grade(score) for score in [33, 99, 77, 70, 89, 90, 100]]
['F', 'A', 'C', 'C', 'B', 'A', 'A']
排序很耗时,因此在得到一个有序序列之后,我们最好能够保持它的有序。 bisect.insort 就是为了这个而存在的。
insort(seq, item) 把变量 item 插入到序列 seq 中,并能保持 seq 的升序顺序。
import bisect
import random
SIZE=7
random.seed(1729)
my_list = []
for i in range(SIZE):
new_item = random.randrange(SIZE*2)
bisect.insort(my_list, new_item)
print('%2d ->' % new_item, my_list)
10 -> [10]
0 -> [0, 10]
6 -> [0, 6, 10]
8 -> [0, 6, 8, 10]
7 -> [0, 6, 7, 8, 10]
2 -> [0, 2, 6, 7, 8, 10]
10 -> [0, 2, 6, 7, 8, 10, 10]
2.9 当列表不是首选时
2.9.1 数组
如果我们需要一个只包含数字的列表,那么 array.array 比 list 更高效。数组支持所有跟可变序列有关的操作,包括 .pop、.insert 和 .extend。另外,数组还提供从文件读取和存入文件的更快的方法,如 .frombytes 和 .tofile。
>>> from array import array
>>> from random import random
>>> floats = array('d', (random() for i in range(10**7)))
>>> floats[-1]
0.07802343889111107
>>> fp = open('floats.bin', 'wb')
>>> floats.tofile(fp)
>>> fp.close()
>>> floats2 = array('d')
>>> fp = open('floats.bin', 'rb')
>>> floats2.fromfile(fp, 10**7)
>>> fp.close()
>>> floats2[-1]
0.07802343889111107
>>> floats2 == floats
True
列表和数组的属性和方法:
| 列表 | 数组 | ||
|---|---|---|---|
| s.__add(s2)__ | ✔ | ✔ | s + s2,拼接 |
| s.__iadd(s2)__ | ✔ | ✔ | s += s2,就地拼接 |
| s.append(e) | ✔ | ✔ | 在尾部添加一个元素 |
| s.byteswap | ✔ | 翻转数组内每个元素的字节序列,转换字节序 | |
| s.clear() | ✔ | 删除所有元素 | |
| s.__contains__(e) | ✔ | ✔ | s 是否含有 e |
| s.copy() | ✔ | 对列表浅复制 | |
| s.__copy__() | ✔ | 对 copy.copy 的支持 | |
| s.count(e) | ✔ | ✔ | s 中 e 出现的次数 |
| s.__deepcopy__() | ✔ | 对 copy.deepcopy 的支持 | |
| s.__delitem__(p) | ✔ | ✔ | 删除位置 p 的元素 |
| s.extend(it) | ✔ | ✔ | 将可迭代对象 it 里的元素添加到尾部 |
| s.frombytes(b) | ✔ | 将压缩成机器值的字节序列读出来添加到尾部 | |
| s.fromfile(f, n) | ✔ | 将二进制文件 f 内含有机器值读出来添加到尾部,最多 | |
| s.fromlist(l) | ✔ | 将列表里的元素添加到尾部,如果其中任何一个元素导致了 TypeError 异常,那么所有的添加都会取消 | |
| s.__getitem__(p) | ✔ | ✔ | s[p],读取位置 p 的元素 |
| s.index(e) | ✔ | ✔ | 找到 e 在序列中第一次出现的位置 |
| s.insert(p, e) | ✔ | ✔ | 在位于 p 的元素之前插入元素 e |
| s.itemsize | ✔ | 数组中每个元素的长度是几个字节 | |
| s.__iter__() | ✔ | ✔ | 返回迭代器 |
| s.__len__() | ✔ | ✔ | len(s),序列的长度 |
| s.__mul__(n) | ✔ | ✔ | s * n,重复拼接 |
| s.__imul__(n) | ✔ | ✔ | s *= n,就地重复拼接 |
| s.__rmul__(n) | ✔ | ✔ | n * s,反向重复拼接* |
| s.pop([p]) | ✔ | ✔ | 删除位于 p 的值并返回这个值,p 的默认值是最后一个元素 |
| s.remove(e) | ✔ | ✔ | 删除序列里第一次出现的 e 元素 |
| s.reverse() | ✔ | ✔ | 就地调转序列中元素的位置 |
| s.__reversed__() | ✔ | 返回一个从尾部开始扫描元素的迭代器 | |
| s.__setitem__(p,e) | ✔ | ✔ | s[p] = e,把位于 p 位置的元素替换成 e |
| s.sort([key],[revers]) | ✔ | 就地排序序列,可选参数有 key 和 reverse | |
| s.tobytes() | ✔ | 把所有元素的机器值用 bytes 对象的形式返回 | |
| s.tofile(f) | ✔ | 把所有元素以机器值的形式写入一个文件 | |
| s.tolist() | ✔ | 把数组转换成列表,列表里的元素类型是数字对象 | |
| s.typecode | ✔ | 返回只有一个字符的字符串,代表数组元素在 C 语言中的类型 |
从 Python 3.4 开始,数组类型不再支持诸如 list.sort() 这种就地排序方法。要给数组排序的话,得用 sorted 函数新建一个数组:
a = array.array(a.typecode, sorted(a))
想要在不打乱次序的情况下为数组添加新的元素,bisect.insort 还是能派上用场。
2.9.2 双向队列和其他形式的队列
利用 .append 和 .pop 方法,我们可以把列表当作栈或者队列来用(比如,把 .append 和 .pop(0) 合起来用,就能模拟栈的 “先进先出” 的特点)。但是删除列表的第一个元素(亦或是在第一个元素之前添加一个元素)之类的操作是很耗时的,因为这些操作会牵扯到移动列表里的所有元素。
collections.deque 类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的数据类型。而且如果想要有一种数据类型来存放 最近用到的几个元素,deque 也是一个很好的选择。这是因为在新建一个双向队列的时候,你可以指定这个队列的大小,如果这个队列满员了,还可以从反向端删除过期的元素,然后在尾端添加新的元素。
>>> from collections import deque
>>> dq = deque(range(10), maxlen=10)
>>> dq
deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.rotate(3) # 旋转操作 n > 0 右边 n 个元素移动到左边
>>> dq
deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
>>> dq.rotate(-4) # n < 0 左边 n 个元素移动到右边
>>> dq
deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)
>>> dq.appendleft(-1) # len(d) == d.maxlen 删除头部元素
>>> dq
deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.extend([11, 22, 33]) # 挤掉头部的元素
>>> dq
deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10)
>>> dq.extendleft([10, 20, 30, 40]) # extendleft(iter) 方法会把迭代器里的元素逐个添加到双向队列的左边,,因此迭代器里的元素会逆序出现在队列里。
>>> dq
deque([40, 30, 20, 10, 3, 4, 5, 6, 7, 8], maxlen=10)
append 和 popleft 都是原子操作,也就说是 deque 可以在多线程程序中安全地当作先进先出的栈使用,而使用者不需要担心资源锁的问题。
列表和双向队列的方法:
| 列表 | 双端队列 | ||
|---|---|---|---|
| s.__add__(s2) | ✔ | s + s2,拼接 | |
| s.__iadd__(s2) | ✔ | ✔ | s += s2,就地拼接 |
| s.append(e) | ✔ | ✔ | 添加一个元素到最右侧(到最后一个元素之后) |
| s.appendleft(e) | ✔ | 添加一个元素到最左侧(到第一个元素之前) | |
| s.clear() | ✔ | ✔ | 删除所有元素 |
| s.__contains__(e) | ✔ | s 是否含有 e | |
| s.copy() | ✔ | 对列表浅复制 | |
| s.__copy__() | ✔ | 对 copy.copy(浅复制)的支持 | |
| s.count(e) | ✔ | ✔ | s 中 e 出现的次数 |
| s.__delitem__(p) | ✔ | ✔ | 把位置 p 的元素移除 |
| s.extend(i) | ✔ | ✔ | 将可迭代对象 i 中的元素添加到尾部 |
| s.extendleft(i) | ✔ | 将可迭代对象 i 中的元素添加到头部 | |
| s.__getitem__(p) | ✔ | ✔ | s[p],读取位置 p 的元素 |
| s.index(e) | ✔ | 找到 e 在序列中第一次出现的位置 | |
| s.insert(p, e) | ✔ | 在位于 p 的元素之前插入元素 e | |
| s.__iter__() | ✔ | ✔ | 返回迭代器 |
| s.__len__() | ✔ | ✔ | len(s),序列的长度 |
| s.__mul__(n) | ✔ | s * n,重复拼接 | |
| s.__imul__(n) | ✔ | s *= n,就地重复拼接 | |
| s.__rmul__(n) | ✔ | n * s,反向重复拼接* | |
| s.pop() | ✔ | ✔ | 移除最后一个元素并返回它的值# |
| s.popleft() | ✔ | 移除第一个元素并返回它的值 | |
| s.remove(e) | ✔ | ✔ | 移除序列里第一次出现的 e 元素 |
| s.reverse() | ✔ | ✔ | 调转序列中元素的位置 |
| s.__reversed__() | ✔ | ✔ | 返回一个从尾部开始扫描元素的迭代器 |
| s.rotate(n) | ✔ | 把 n 个元素从队列的一端移到另一端 | |
| s.__setitem__(p, e) | ✔ | ✔ | s[p] = e,把位于 p 位置的元素替换成 e |
| s.sort([key], [revers]) | ✔ | 就地排序序列,可选参数有 key 和 reverse |
# a_list.pop(p) 这个操作只能用于列表,双向队列的这个方法不接收参数。
除了 deque 之外,还有些其他的 Python 标准库也有对队列的实现。
-
queue
提供了同步(线程安全)类 Queue、LifoQueue 和 PriorityQueue,不同的线程可以利用这些数据类型来交换信息。这三个类的构造方法都有一个可选参数 maxsize,它接收正整数作为输入值,用来限定队列的大小。但是在满员的时候,这些类不会扔掉旧的元素来腾出位置。相反,如果队列满了,它就会被锁住,直到另外的线程移除了某个元素而腾出了位置。这一特性让这些类很适合用来控制活跃线程的数量。
-
multiprocessing
这个包实现了自己的 Queue,它跟 queue.Queue 类似,是设计给进程间通信用的。同时还有一个专门的 multiprocessing.JoinableQueue 类型,可以让任务管理变得更方便。
-
asyncio
Python 3.4 新提供的包,里面有 Queue、LifoQueue、PriorityQueue 和
JoinableQueue,这些类受到 queue 和 multiprocessing 模块的影响,但是为异步编程里的任务管理提供了专门的便利。 -
heapq
跟上面三个模块不同的是,heapq 没有队列类,而是提供了 heappush 和 heappop方法,让用户可以把可变序列当作堆队列或者优先队列来使用。
3. 字典和集合
dict 类型不但在各种程序里广泛使用,它也是 Python 语言的基石。模块的命名空间、实例的属性和函数的关键字参数中都可以看到字典的身影。跟它有关的内置函数都在 __builtins__.__dict__模块中。
3.1 字典创建方法
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> f = dict({'one': 1, 'three': 3}, two=2)
>>> a == b == c == d == e == f
True
字典推导(dictcomp):
>>> DIAL_CODES = [
... (86, 'China'),
... (91, 'India'),
... (1, 'United States'),
... (62, 'Indonesia'),
... (55, 'Brazil'),
... (92, 'Pakistan'),
... (880, 'Bangladesh'),
... (234, 'Nigeria'),
... (7, 'Russia'),
... (81, 'Japan'),
... ]
>>> country_code = {country: code for code, country in DIAL_CODES}
>>> country_code
{'China': 86, 'India': 91, 'Bangladesh': 880, 'United States': 1,
'Pakistan': 92, 'Japan': 81, 'Russia': 7, 'Brazil': 55, 'Nigeria':
234, 'Indonesia': 62}
>>> {code: country.upper() for country, code in country_code.items() if code < 66}
{1: 'UNITED STATES', 55: 'BRAZIL', 62: 'INDONESIA', 7: 'RUSSIA'}
3.2 常见的映射方法
dict、collections.defaultdict 和 collections.OrderedDict 这三种映射
类型的方法列表:
| dict | defaultdict | OrderedDict | ||
|---|---|---|---|---|
| d.clear() | ✔ | ✔ | ✔ | 移除所有元素 |
| d.__contains__(k) | ✔ | ✔ | ✔ | 检查 k 是否在 d 中 |
| d.copy() | ✔ | ✔ | ✔ | 浅复制 |
| d.__copy__() | ✔ | 用于支持 copy.copy | ||
| d.default_factory | ✔ | 在 __missing__ 函数中被调用的函数,用以给未找到的元素设置值* | ||
| d.__delitem__(k) | ✔ | ✔ | ✔ | del d[k],移除键为 k 的元素 |
| d.fromkeys(it,[initial]) | ✔ | ✔ | ✔ | 将迭代器 it 里的元素设置为映射里的键,如果有 initial 参数,就把它作为这些键对应的值(默认是 None) |
| d.get(k,[default]) | ✔ | ✔ | ✔ | 返回键 k 对应的值,如果字典里没有键 k,则返回 None 或者 default |
| d.__getitem__(k) | ✔ | ✔ | ✔ | 让字典 d 能用 d[k] 的形式返回键 k 对应的值 |
| d.items() | ✔ | ✔ | ✔ | 返回 d 里所有的键值对 |
| d.__iter__() | ✔ | ✔ | ✔ | 获取键的迭代器 |
| d.keys() | ✔ | ✔ | ✔ | 获取所有的键 |
| d.__len__() | ✔ | ✔ | ✔ | 可以用 len(d) 的形式得到字典里键值对的数量 |
| d.__missing__(k) | ✔ | 当 __getitem__ 找不到对应键的时候,这个方法会被调 | ||
| 用 | ||||
| d.move_to_end(k,[last]) | ✔ | 把键为 k 的元素移动到最靠前或者最靠后的位置(last 的默认值是 True) | ||
| d.pop(k, [defaul]) | ✔ | ✔ | ✔ | 返回键 k 所对应的值,然后移除这个键值对。如果没有这个键,返回 None 或者 defaul |
| d.popitem() | ✔ | ✔ | ✔ | 随机返回一个键值对并从字典里移除它# |
| d.__reversed__() | ✔ | 返回倒序的键的迭代器 | ||
| d.setdefault(k,[default]) | ✔ | ✔ | ✔ | 若字典里有键k,则返回这个值;若无,则让 d[k] = default,然后返回 default |
| d.__setitem__(k, v) | ✔ | ✔ | ✔ | 实现 d[k] = v 操作,把 k 对应的值设为 v |
| d.update(m,[**kargs]) | ✔ | ✔ | ✔ | m 可以是映射或者键值对迭代器,用来更新 d 里对应的条目 |
| d.values() | ✔ | ✔ | ✔ | 返回字典里的所有值 |
* default_factory 并不是一个方法,而是一个可调用对象(callable),它的值在 defaultdict 初始化的时候由用户
设定。
# OrderedDict.popitem() 会移除字典里最先插入的元素(先进先出);同时这个方法还有一个可选的 last 参数,若
为真,则会移除最后插入的元素(后进先出)。
3.3 用 setdefault 处理找不到的键
"""创建从一个单词到其出现情况的映射"""
import sys
import re
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
index.setdefault(word, []).append(location)
# 以字母顺序打印出结果
for word in sorted(index, key=str.upper):
print(word, index[word])
3.4 映射的弹性键查询
3.4.1 defaultdict:处理找不到的键的一个选择
在实例化一个 defaultdict 的时候,需要给构造方法提供一个可调用对象,这个可调用对象会在 __getitem__ 碰到找不到的键的时候被调用,让 __getitem__ 返
回某种默认值。
index = collections.defaultdict(list)
index[word].append(location)
把 list 构造方法作为 default_factory 来创建一个 defaultdict。
如果 index 并没有 word 的记录,那么 default_factory 会被调用,为查询不到的键创造一个值。这个值在这里是一个空的列表,然后这个空列表被赋值给 index[word],继而被当作返回值返回,因此 .append(location) 操作总能成功。
defaultdict 里的 default_factory 只会在 __getitem__ 里被调用,在其他的方法里完全不会发挥作用。比如,dd 是个 defaultdict,k 是个找不到的键, dd[k] 这个表达式会调用 default_factory 创造某个默认值,而 dd.get(k) 则会返回 None。
所有这一切背后的功臣其实是特殊方法 __missing__。它会在 defaultdict 遇到找不到的键的时候调用 default_factory,而实际上这个特性是所有映射类型都可以选择去支持的。
3.4.2 特殊方法 __missing__
__missing__ 方法只会被 __getitem__ 调用(比如在表达式 d[k] 中)。提供 __missing__ 方法对 get 或者 __contains__(in 运算符会用到这个方法)这些方法的使用没有影响。
class StrKeyDict0(dict): # 继承 dict
def __missing__(self, key):
if isinstance(key, str): # 如果找不到的键本身就是字符串 -> KeyError 防止递归调用
raise KeyError(key)
return self[str(key)] # 找不到的的键不是字符串 -> str(key)
def get(self, key, default=None):
try:
return self[key] # -> self[key] -> __getitem__ -> not find then __missing__
except KeyError:
return default
def __contains__(self, key): # key not -> str(key)
return key in self.keys() or str(key) in self.keys()
3.5 字典的变种
-
collections.OrderedDict
这个类型在添加键的时候会保持顺序,因此键的迭代次序总是一致的。OrderedDict 的 popitem 方法默认删除并返回的是字典里的最后一个元素,但是如果像 my_odict.popitem(last=False) 这样调用它,那么它删除并返回第一个被添加进去的元素。
-
该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。这个功能在给有嵌套作用域的语言做解释器的时候很有用,可以用一个映射对象来代表一个作用域的上下文。
Python 变量查询规则:
import builtins pylookup = ChainMap(locals(), globals(), vars(builtins)) -
collections.Counter
这个映射类型会给键准备一个整数计数器。每次更新一个键的时候都会增加这个计数器。所以这个类型可以用来给可散列表对象计数,或者是当成多重集来用——多重集合就是集合里的元素可以出现不止一次。Counter 实现了 + 和 - 运算符用来合并记录,还有像 most_common([n]) 这类很有用的方法。most_common([n]) 会按照次序返回映射里最常见的 n 个键和它们的计数。
单词中各个字母出现的次数:
>>> ct = collections.Counter('abracadabra') >>> ct Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1}) >>> ct.update('aaaaazzz') >>> ct Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1}) >>> ct.most_common(2) [('a', 10), ('z', 3)] -
colllections.UserDict
这个类其实就是把标准 dict 用纯 Python 又实现了一遍。跟 OrderedDict、ChainMap 和 Counter 这些开箱即用的类型不同,UserDict 是让用户继承写子类的。
3.6 子类化 UserDict
而更倾向于从 UserDict 而不是从 dict 继承的主要原因是,后者有时会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但是 UserDict 就不会带来这些问题。
UserDict 并不是 dict 的子类,但是 UserDict 有一个叫作 data 的属性,是 dict 的实例,这个属性实际上是 UserDict 最终存储数据的地方。
import collections
class StrKeyDict(collections.UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, item):
self.data[str(key)] = item
因为 UserDict 继承的是 MutableMapping,所以 StrKeyDict 里剩下的那些映射类型的方法都是从 UserDict、MutableMapping 和 Mapping 这些超类继承而来的。特别是最后的 Mapping 类,它虽然是一个抽象基类(ABC),但它却提供了好几个实用的方法。以下两个方法值得关注。
-
MutableMapping.update
这个方法不但可以为我们所直接利用,它还用在 __init__ 里,让构造方法可以利用传入的各种参数(其他映射类型、元素是 (key, value) 对的可迭代对象和键值参数)来新建实例。因为这个方法在背后是用 self[key] = value 来添加新值的,所以它其实是在使用我们的 __setitem__ 方法。
-
Mapping.get
在 StrKeyDict0 中,我们不得不改写 get 方法,好让它的表现跟 __getitem__ 一致。而在上面的示例中就没这个必要了,因为它继承了 Mapping.get 方法,而 Python 的源码 显示,这个方法的实现方式跟 StrKeyDict0.get 是一模一样的。
3.7 不可变映射序列
从 Python 3.3 开始,types 模块中引入了一个封装类名叫 MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。
>>> from types import MappingProxyType
>>> d = {1:'A'}
>>> d_proxy = MappingProxyType(d)
>>> d_proxy
mappingproxy({1: 'A'})
>>> d_proxy[1]
'A'
>>> d_proxy[2] = 'x' # 只读
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'mappingproxy' object does not support item assignment
>>> d[2] = 'B' # 可修改
>>> d_proxy
mappingproxy({1: 'A', 2: 'B'})
>>> d_proxy[2]
'B'
3.8 集合论
集合中的元素必须是可散列的,set 类型本身是不可散列的,但是 frozenset 可以。因此可以创建一个包含不同 frozenset 的 set。
除了保证唯一性,集合还实现了很多基础的中缀运算符。给定两个集合 a 和 b,a | b 返回的是它们的合集,a & b 得到的是交集,而 a - b 得到的是差集。合理地利用这些操作,不仅能够让代码的行数变少,还能减少 Python 程序的运行时间。这样做同时也是为了让代码更易读,从而更容易判断程序的正确性,因为利用这些运算符可以省去不必要的循环和逻辑操作。
found = len(set(needles) & set(haystack))
found = len(set(needles).intersection(haystack))
3.8.1 集合字面量
>>> s = {1}
>>> type(s)
<class 'set'>
>>> s
{1}
>>> s.pop()
1
>>> s
set()
>>> frozenset(range(10))
frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
3.8.2 集合推导
>>> from unicodedata import name
>>> {chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i), '')}
{'§', '=', '¢', '#', '¤', '<', '¥', 'μ', '×', '$', '¶', '£', '©', '°', '+', '÷', '±', '>', '¬', '®', '%'}
3.8.3 集合的操作
集合的数学运算:
| 数学符号 | Python运算符 | 方法 | 描述 |
|---|---|---|---|
| S ∩ Z | s & z | s.__and__(z) | s 和 z 的交集 |
| S ∩ Z | z & s | s.__rand__(z) | 反向 & 操作 |
| S ∩ Z | z & s | s.intersection(it, ...) | 把可迭代的 it 和其他所有参数转化为集合,然后求它们与 s 的交集 |
| S ∩ Z | s &= z | s.__iand__(z) | 把 s 更新为 s 和 z 的交集 |
| S ∩ Z | s &= z | s.intersection_update(it, ...) | 把可迭代的 it 和其他所有参数转化为集合,然后求得它们与 s 的交集,然后把 s 更新成这个交集 |
| S ∪ Z | s | z | s.__or__(z) | s 和 z 的并集 |
| S ∪ Z | z | s | s.__ror__(z) | | 的反向操作 |
| S ∪ Z | z | s | s.union(it, ...) | 把可迭代的 it 和其他所有参数转化为集合,然后求它们和 s 的并集 |
| S ∪ Z | s |= z | s.__ior__(z) | 把 s 更新为 s 和 z 的并集 |
| S ∪ Z | s |= z | s.update(it, ...) | 把可迭代的 it 和其他所有参数转化为集合,然后求它们和 s 的并集,并把 s 更新成这个并集 |
| S \ Z | s - z | s.__sub__(z) | s 和 z 的差集,或者叫作相对补集 |
| S \ Z | z - s | s.__rsub__(z) | - 的反向操作 |
| S \ Z | z - s | s.difference(it, ...) | 把可迭代的 it 和其他所有参数转化为集合,然后求它们和 s 的差集 |
| S \ Z | s -= z | s.__isub__(z) | 把 s 更新为它与 z 的差集 |
| S \ Z | s -= z | s.difference_update(it, ...) | 把可迭代的 it 和其他所有参数转化为集合,求它们和 s 的差集,然后把 s 更新成这个差集 |
| S \ Z | s -= z | s.symmetric_difference(it) | 求 s 和 set(it) 的对称差集 |
| S △ Z | s ^ z | s.__xor__(z) | 求 s 和 z 的对称差集 |
| S △ Z | z ^ s | s.__rxor__(z) | ^ 的反向操作 |
| S △ Z | z ^ s | s.symmetric_difference_update(it,...) | 把可迭代的 it 和其他所有参数转化为集合,然后求它们和 s 的对称差集,最后把 s 更新成该结果 |
| S △ Z | s ^= z | s.__ixor__(z) | 把 s 更新成它与 z 的对称差集 |
集合的比较运算符:
| 数学符号 | Python运算符 | 方法 | 描述 |
|---|---|---|---|
| s.isdisjoint(z) | 查看 s 和 z 是否不相交(没有共同元素) | ||
| e ∈ S | e in s | s.__contains__(e) | 元素 e 是否属于 s |
| S ⊆ Z | s <= z | s.__le__(z) | s 是否为 z 的子集 |
| s.issubset(it) | 把可迭代的 it 转化为集合,然后查看 s 是否为它的子集 | ||
| S ⊂ Z | s < z | s.__lt__(z) | s 是否为 z 的真子集 |
| S ⊇ Z | s >= z | s.__ge__(z) | s 是否为 z 的父集 |
| s.issuperset(it) | 把可迭代的 it 转化为集合,然后查看 s 是否为它的父集 | ||
| S ⊃ Z | s > z | s.__gt__(z) | s 是否为 z 的真父集 |
集合类型的其他方法:
| set | frozenset | ||
|---|---|---|---|
| s.add(e) | ✔ | 把元素 e 添加到 s 中 | |
| s.clear() | ✔ | 移除掉 s 中的所有元素 | |
| s.copy() | ✔ | ✔ | 对 s 浅复制 |
| s.discard(e) | ✔ | 如果 s 里有 e 这个元素的话,把它移除 | |
| s.__iter__() | ✔ | ✔ | 返回 s 的迭代器 |
| s.__len__() | ✔ | ✔ | len(s) |
| s.pop() | ✔ | 从 s 中移除一个元素并返回它的值,若 s 为空,则抛出 KeyError 异常 | |
| s.remove(e) | ✔ | 从 s 中移除 e 元素,若 e 元素不存在,则抛出 KeyError 异常 |
3.9 dict 和 set 的背后
3.9.1 字典中的散列表
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。在一般的数据结构教材中,散列表里的单元通常叫作表元(bucket)。在 dict 的散列表当中,每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所以可以通过偏移量来读取某个表元。
因为 Python 会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面。
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。Python 中可以用 hash() 方法来做这件事情。
-
散列值和相等性
内置的 hash() 方法可以用于所有的内置类型对象。如果是自定义对象调用 hash()的话,实际上运行的是自定义的 __hash__。如果两个对象在比较的时候是相等的,那它们的散列值必须相等,否则散列表就不能正常运行了。
-
散列表算法
为了获取 my_dict[search_key] 背后的值,Python 首先会调用 hash(search_key) 来计算 search_key 的散列值,把这个值最低的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看当前散列表的大小)。若找到的表元是空的,则抛出 KeyError 异常。若不是空的,则表元里会有一对 found_key:found_value。这时候 Python 会检验 search_key == found_key 是否为真,如果它们相等的话,就会返回 found_value。
如果 search_key 和 found_key 不匹配的话,这种情况称为散列冲突。发生这种情况是因为,散列表所做的其实是把随机的元素映射到只有几位的数字上,而散列表本身的索引又只依赖于这个数字的一部分。为了解决散列冲突,算法会在散列值中另外再取几位,然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表元。
若这次找到的表元是空的,则同样抛出 KeyError;若非空,或者键匹配,则返回这个值;或者又发现了散列冲突,则重复以上的步骤。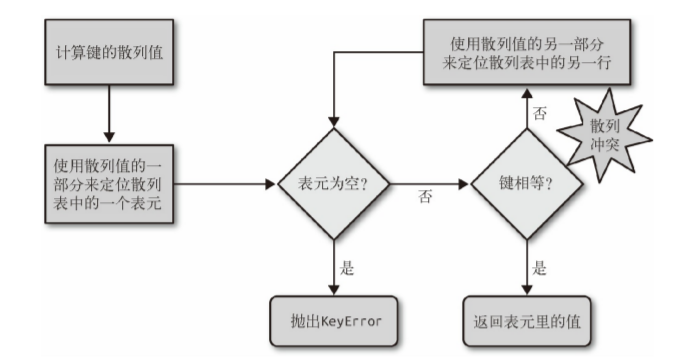
另外在插入新值时,Python 可能会按照散列表的拥挤程度来决定是否要重新分配内存为它扩容。如果增加了散列表的大小,那散列值所占的位数和用作索引的位数都会随之增加,这样做的目的是为了减少发生散列冲突的概率。
CPython 的实现细节里有一条是:如果有一个整型对象,而且它能被存进一个机器字中,那么它的散列值就是它本身的值。
3.9.2 dict 的实现及其导致的结果
-
键必须是可散列的
一个可散列的对象必须满足以下要求。
(1) 支持 hash() 函数,并且通过 __hash__() 方法所得到的散列值是不变的。
(2) 支持通过 __eq__() 方法来检测相等性。
(3) 若 a == b 为真,则 hash(a) == hash(b) 也为真。
所有由用户自定义的对象默认都是可散列的,因为它们的散列值由
id()来获取,而且它们都是不相等的。 -
字典在内存上的开销巨大
由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下。
举例而言,如果你需要存放数量巨大的记录,那么放在由元组或是具名元组构成的列表中会是比较好的选择;最好不要根据 JSON 的风格,用由字典组成的列表来存放这些记录。用元组取代字典就能节省空间的原因有两个:其一是避免了散列表所耗费的空间,其二是无需把记录中字段的名字在每个元素里都存一遍。在用户自定义的类型中,__slots__ 属性可以改变实例属性的存储方式,由 dict 变成 tuple。
-
键查询很快
dict 的实现是典型的空间换时间:字典类型有着巨大的内存开销,但它们提供了无视数据量大小的快速访问——只要字典能被装在内存里。如果把字典的大小从 1000 个元素增加到 10 000 000 个,查询时间也不过是原来的 2.8 倍,从 0.000163 秒增加到了 0.00456 秒。这意味着在一个有 1000 万个元素的字典里,每秒能进行 200 万个键查询。
-
键的次序取决于添加顺序
当往 dict 里添加新键而又发生散列冲突的时候,新键可能会被安排存放到另一个位置。于是下面这种情况就会发生:由 dict([key1, value1], [key2, value2)] 和 dict([key2, value2], [key1, value1]) 得到的两个字典,在进行比较的时候,它们是相等的;但是如果在 key1 和 key2 被添加到字典里的过程中有冲突发生的话,这两个键出现在字典里的顺序是不一样的。
-
往字典里添加新键可能会改变已有键的顺序
无论何时往字典里添加新的键,Python 解释器都可能做出为字典扩容的决定。扩容导致的结果就是要新建一个更大的散列表,并把字典里已有的元素添加到新表里。
3.9.3 set 的实现以及导致的结果
set 和 frozenset 的实现也依赖散列表,但在它们的散列表里存放的只有元素的引用(就像在字典里只存放键而没有相应的值)。
- 集合里的元素必须是可散列的。
- 集合很消耗内存。
- 可以很高效地判断元素是否存在于某个集合。
- 元素的次序取决于被添加到集合里的次序。
- 往集合里添加元素,可能会改变集合里已有元素的次序。
4. 文本和字节序列
处理文本文件
处理文本的最佳实践是“Unicode 三明治”(如图 4-2 所示)。 意思是,要尽早把输入(例如读取文件时)的字节序列解码成字符串。这种三明治中的“肉片”是程序的业务逻辑,在这里只能处理字符串对象。在其他处理过程中,一定不能编码或解码。对输出来说,则要尽量晚地把字符串编码成字节序列。多数 Web 框架都是这样做的,使用框架时很少接触字节序列。例如,在 Django 中,视图应该输出 Unicode 字符串;Django 会负责把响应编码成字节序列,而且默认使用 UTF-8 编码。
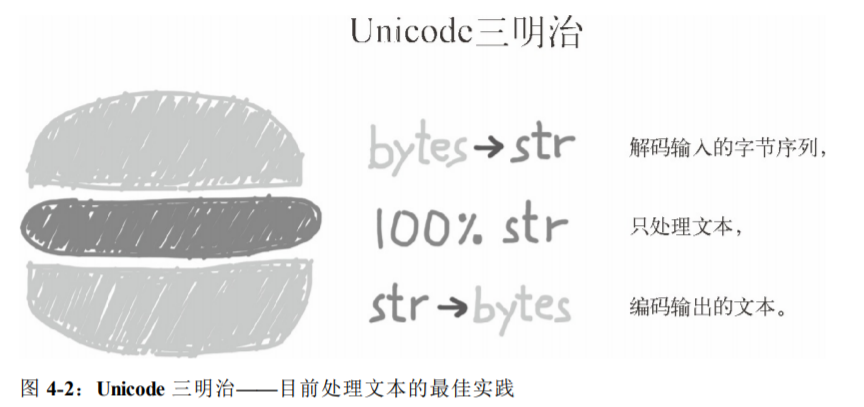
在 Python 3 中能轻松地采纳 Unicode 三明治的建议,因为内置的 open 函数会在读取文件时做必要的解码,以文本模式写入文件时还会做必要的编码,所以调用 my_file.read() 方法得到的以及传给 my_file.write(text) 方法的都是字符串对象。
需要在多台设备中或多种场合下运行的代码,一定不能依赖默认编码。打开文
件时始终应该明确传入 encoding= 参数,因为不同的设备使用的默认编码可能不同,有时隔一天也会发生变化。
-
如果打开文件时没有指定 encoding 参数,默认值由 locale.getpreferredencoding() 提供。
-
如果设定了 PYTHONIOENCODING 环境变量, sys.stdout/stdin/stderr 的编码使用设定的值;否则,继承自所在的控制台;如果输入 / 输出重定向到文件,则由 locale.getpreferredencoding() 定义。
-
Python 在二进制数据和字符串之间转换时,内部使用 sys.getdefaultencoding() 获得的编码;Python 3 很少如此,但仍有发生。这个设置不能修改。
-
sys.getfilesystemencoding() 用于编解码文件名(不是文件内容)。把字符串参数作为文件名传给 open() 函数时就会使用它;如果传入的文件名参数是字节序列,那就不经改动直接传给 OS API。
5. 一等对象
在 Python 中,函数是一等对象。编程语言理论家把 一等对象 定义为满足下述条件的程序实体:
- 在运行时创建
- 能赋值给变量或数据结构中的元素
- 能作为参数传给函数
- 能作为函数的返回结果
5.1 高阶函数
接受函数为参数,或者把函数作为结果返回的函数是 高阶函数(higher-order
function)。map 函数就是一例,此外,内置函数 sorted 也是。
# 根据单词长度给一个列表排序
>>> fruits = ['strawberry', 'fig', 'apple', 'cherry', 'raspberry', 'banana']
>>> sorted(fruits, key=len)
['fig', 'apple', 'cherry', 'banana', 'raspberry', 'strawberry']
# 根据反向拼写给一个单词列表排序
>>> def reverse(word):
... return word[::-1]
>>> reverse('testing')
'gnitset'
>>> sorted(fruits, key=reverse)
['banana', 'apple', 'fig', 'raspberry', 'strawberry', 'cherry']
列表推导或生成器表达式具有 map 和 filter 两个函数的功能,而且更易于阅读。
>>> list(map(fact, range(6))) # map
[1, 1, 2, 6, 24, 120]
>>> [fact(n) for n in range(6)] # 列表推导
[1, 1, 2, 6, 24, 120]
>>> list(map(factorial, filter(lambda n: n % 2, range(6)))) # filter
[1, 6, 120]
>>> [factorial(n) for n in range(6) if n % 2] # 列表推导
[1, 6, 120]
reduce 和 sum:
>>> from functools import reduce
>>> from operator import add
>>> reduce(add, range(100))
4950
>>> sum(range(100))
4950
all 和 any 也是内置的归约函数:
-
all(iterable)
如果 iterable 的每个元素都是真值,返回 True;all([]) 返回 True
-
any(iterable)
只要 iterable 中有元素是真值,就返回 True;any([]) 返回 False。
5.2 匿名函数
lambda 关键字在 Python 表达式内创建匿名函数,在参数列表中最适合使用匿名函数。
>>> fruits = ['strawberry', 'fig', 'apple', 'cherry', 'raspberry', 'banana']
>>> sorted(fruits, key=lambda word: word[::-1])
['banana', 'apple', 'fig', 'raspberry', 'strawberry', 'cherry']
lambda 句法只是语法糖:与 def 语句一样,lambda 表达式会创建函数对象。这是 Python 中几种可调用对象的一种。
5.3 可调用对象
除了用户定义的函数,调用运算符(即 ())还可以应用到其他对象上。如果想判断对象能否调用,可以使用内置的 callable() 函数。Python 数据模型文档列出了 7 种可调用对象。
-
用户定义的函数
使用 def 语句或 lambda 表达式创建。
-
内置函数
使用 C 语言(CPython)实现的函数,如 len 或 time.strftime。
-
内置方法
使用 C 语言实现的方法,如 dict.get。
-
方法
在类的定义体中定义的函数。
-
类
调用类时会运行类的 __new__ 方法创建一个实例,然后运行 __init__ 方法,初始化实例,最后把实例返回给调用方。因为 Python 没有 new 运算符,所以调用类相当于调用函数。
-
类的实例
如果类定义了 __call__ 方法,那么它的实例可以作为函数调用。
-
生成器函数
使用 yield 关键字的函数或方法。调用生成器函数返回的是生成器对象。
>>> abs, str, 13
(<built-in function abs>, <class 'str'>, 13)
>>> [callable(obj) for obj in (abs, str, 13)]
[True, True, False]
5.4 用户定义的可调用类型
import random
class BingoCage:
def __init__(self, items):
self._items = list(items)
random.shuffle(self._items)
def pick(self):
try:
return self._items.pop()
except IndexError:
raise LookupError('pick from empty BingoCage')
def __call__(self):
return self.pick()
实现 __call__ 方法的类是创建函数类对象的简便方式,此时必须在内部维护一个状态,让它在调用之间可用,例如 BingoCage 中的剩余元素。装饰器就是这样。装饰器必须是函数,而且有时要在多次调用之间“记住”某些事 [ 例如备忘(memoization),即缓存消耗
大的计算结果,供后面使用 ]。
创建保有内部状态的函数,还有一种截然不同的方式——使用闭包。
5.5 函数内省
除了 __doc__,函数对象还有很多属性。使用 dir 函数可以探知 factorial 具有下述属性:
>>> dir(factorial)
['__annotations__', '__call__', '__class__', '__closure__', '__code__',
'__defaults__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__get__', '__getattribute__', '__globals__',
'__gt__', '__hash__', '__init__', '__kwdefaults__', '__le__', '__lt__',
'__module__', '__name__', '__ne__', '__new__', '__qualname__', '__reduce__',
'__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__',
'__subclasshook__']
列出常规对象没有而函数有的属性:
>>> class C: pass
>>> obj = C()
>>> def func(): pass
>>> sorted(set(dir(func)) - set(dir(obj)))
['__annotations__', '__call__', '__closure__', '__code__', '__defaults__',
'__get__', '__globals__', '__kwdefaults__', '__name__', '__qualname__']
用户定义的函数的属性:
| 名称 | 类型 | 说明 |
|---|---|---|
| __annotations__ | dict | 参数和返回值的注解 |
| __call__ | method-wrapper | 实现 () 运算符;即可调用对象协议 |
| __closure__ | tuple | 函数闭包,即自由变量的绑定(通常是 None) |
| __code__ | code | 编译成字节码的函数元数据和函数定义体 |
| __defaults__ | tuple | 形式参数的默认值 |
| __get__ | method-wrapper | 实现只读描述符协议(参见第 20 章) |
| __globals__ | dict | 函数所在模块中的全局变量 |
| __kwdefaults__ | dict | 仅限关键字形式参数的默认值 |
| __name__ | str | 函数名称 |
| __qualname__ | str | 函数的限定名称,如 Random.choice( 参阅PEP 3155,https://www.python.org/dev/peps/pep-3155/) |
5.6 从定位参数到仅限关键字参数
Python 最好的特性之一是提供了极为灵活的参数处理机制,而且 Python 3 进一步提供了仅限关键字参数(keyword-only argument)。与之密切相关的是,调用函数时使用 * 和 ** “展开”可迭代对象,映射到单个参数。
def tag(name, *content, cls=None, **attrs):
"""生成一个或多个HTML标签"""
if cls is not None:
attrs['class'] = cls
if attrs:
attr_str = ''.join(' %s="%s"' % (attr, value)
for attr, value
in sorted(attrs.items()))
else:
attr_str = ''
if content:
return '\n'.join('<%s%s>%s</%s>' %
(name, attr_str, c, name) for c in content)
else:
return '<%s%s />' % (name, attr_str)
inspect.signature 函数返回一个 inspect.Signature 对象,它有一
个 parameters 属性,这是一个有序映射,把参数名和 inspect.Parameter 对象对应起来。各个 Parameter 属性也有自己的属性,例如 name、default 和 kind。特殊的 inspect._empty 值表示没有默认值,考虑到 None 是有效的默认值(也经常这么做),而且这么做是合理的。
inspect.Signature 对象有个 bind 方法,它可以把任意个参数绑定到签名中的形参上,所用的规则与实参到形参的匹配方式一样。框架可以使用这个方法在真正调用函数前验证参数。
>>> import inspect
>>> sig = inspect.signature(tag)
>>> my_tag = {'name': 'img', 'title': 'Sunset Boulevard',
... 'src': 'sunset.jpg', 'cls': 'framed'}
>>> bound_args = sig.bind(**my_tag)
>>> bound_args
<inspect.BoundArguments object at 0x...>
>>> for name, value in bound_args.arguments.items()
... print(name, '=', value)
...
name = img
cls = framed
attrs = {'title': 'Sunset Boulevard', 'src': 'sunset.jpg'}
>>> del my_tag['name']
>>> bound_args = sig.bind(**my_tag)
Traceback (most recent call last):
...
TypeError: 'name' parameter lacking default value
5.7 函数注解
Python 3 提供了一种句法,用于为函数声明中的参数和返回值附加元数据。
def clip(text:str, max_len:'int > 0'=80) -> str:
"""在max_len前面或后面的第一个空格处截断文本"""
end = None
if len(text) > max_len:
space_before = text.rfind(' ', 0, max_len)
if space_before >= 0:
end = space_before
else:
space_after = text.find(' ', max_len)
if space_after >= 0:
end = space_after
if end is None: # 没找到空格
end = len(text)
return text[:end].rstrip()
Python 对注解所做的唯一的事情是,把它们存储在函数的 __annotations__ 属性里。仅此而已,Python 不做检查、不做强制、不做验证,什么操作都不做。换句话说,注解对Python 解释器没有任何意义。注解只是元数据,可以供 IDE、框架和装饰器等工具使用。唯有 inspect.signature() 函数知道怎么提取注解。
>>> from clip_annot import clip
>>> clip.__annotations__
{'text': <class 'str'>, 'max_len': 'int > 0', 'return': <class 'str'>}
>>> from clip_annot import clip
>>> from inspect import signature
>>> sig = signature(clip)
>>> sig.return_annotation
<class 'str'>
>>> for param in sig.parameters.values():
... note = repr(param.annotation).ljust(13)
... print(note, ':', param.name, '=', param.default)
<class 'str'> : text = <class 'inspect._empty'>
'int > 0' : max_len = 80
5.8 支持函数式编程的包
5.8.1 operator 模块
在函数式编程中,经常需要把算术运算符当作函数使用。例如,不使用递归计算阶乘。求和可以使用 sum 函数,但是求积则没有这样的函数。我们可以使用 reduce 函数,但是需要一个函数计算序列中两个元素之积。
使用 reduce 函数和一个匿名函数计算阶乘:
# 计算阶乘
from functools import reduce
def fact(n):
return reduce(lambda a, b: a*b, range(1, n+1))
使用 reduce 和 operator.mul 函数计算阶乘:
from functools import reduce
from operator import mul
def fact(n):
return reduce(mul, range(1, n+1))
itemgetter 使用 [] 运算符,因此它不仅支持序列,还支持映射和任何实现
__getitem__ 方法的类。
attrgetter 与 itemgetter 作用类似,它创建的函数根据名称提取对象的属性。如果把多个属性名传给 attrgetter,它也会返回提取的值构成的元组。此外,如果参数名中包含 .(点号),attrgetter 会深入嵌套对象,获取指定的属性。
>>> from collections import namedtuple
>>> LatLong = namedtuple('LatLong', 'lat long')
>>> Metropolis = namedtuple('Metropolis', 'name cc pop coord')
>>> metro_areas = [Metropolis(name, cc, pop, LatLong(lat, long))
... for name, cc, pop, (lat, long) in metro_data]
>>> metro_areas[0]
Metropolis(name='Tokyo', cc='JP', pop=36.933, coord=LatLong(lat=35.689722,
long=139.691667))
>>> metro_areas[0].coord.lat
35.689722
>>> from operator import attrgetter
>>> name_lat = attrgetter('name', 'coord.lat')
>>> for city in sorted(metro_areas, key=attrgetter('coord.lat')):
... print(name_lat(city))
('Sao Paulo', -23.547778)
('Mexico City', 19.433333)
('Delhi NCR', 28.613889)
('Tokyo', 35.689722)
('New York-Newark', 40.808611)
operator 模块中定义的部分函数(省略了以 _ 开头的名称,因为它们基本上是实现细节):
>>> [name for name in dir(operator) if not name.startswith('_')]
['abs', 'add', 'and_', 'attrgetter', 'concat', 'contains',
'countOf', 'delitem', 'eq', 'floordiv', 'ge', 'getitem', 'gt',
'iadd', 'iand', 'iconcat', 'ifloordiv', 'ilshift', 'imod', 'imul',
'index', 'indexOf', 'inv', 'invert', 'ior', 'ipow', 'irshift',
'is_', 'is_not', 'isub', 'itemgetter', 'itruediv', 'ixor', 'le',
'length_hint', 'lshift', 'lt', 'methodcaller', 'mod', 'mul', 'ne',
'neg', 'not_', 'or_', 'pos', 'pow', 'rshift', 'setitem', 'sub',
'truediv', 'truth', 'xor']
5.8.2 使用 functools.partial 冻结参数
functools.partial 这个高阶函数用于部分应用一个函数。部分应用是指,基`于一个函数创建一个新的可调用对象,把原函数的某些参数固定。使用这个函数可以把接受一个或多个参数的函数改编成需要回调的 API,这样参数更少。
使用 partial 把一个两参数函数改编成需要单参数的可调用对象:
>>> from operator import mul
>>> from functools import partial
>>> triple = partial(mul, 3)
>>> triple(7)
21
>>> list(map(triple, range(1, 10)))
[3, 6, 9, 12, 15, 18, 21, 24, 27]
6. 使用一等函数实现策略模式
6.1 案例分析:重构“策略”模式
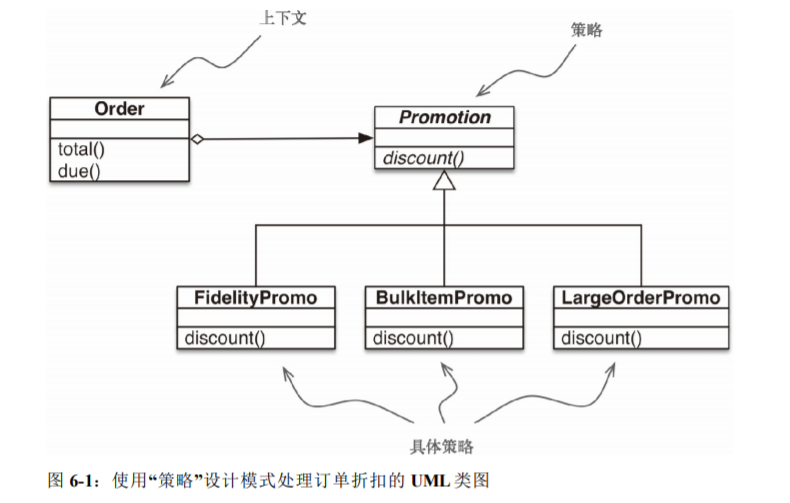
6.1.1 经典的“策略”模式
策略模式: 定义一系列算法,把它们一一封装起来,并且使它们可以相互替换。本模式使得算法可以独立于使用它的客户而变化。
from abc import ABC, abstractmethod
from collections import namedtuple
Customer = namedtuple('Customer', 'name fidelity')
class LineItem:
def __init__(self, product, quantity, price):
self.product = product
self.quantity = quantity
self.price = price
def total(self):
return self.price * self.quantity
class Order: # 上下文
def __init__(self, customer, cart, promotion=None):
self.customer = customer
self.cart = list(cart)
self.promotion = promotion
def total(self):
if not hasattr(self, '__total'):
self.__total = sum(item.total() for item in self.cart)
return self.__total
def due(self):
if self.promotion is None:
discount = 0
else:
discount = self.promotion.discount(self)
return self.total() - discount
def __repr__(self):
fmt = '<Order total: {:.2f} due: {:.2f}>'
return fmt.format(self.total(), self.due())
class Promotion(ABC) : # 策略:抽象基类
@abstractmethod
def discount(self, order):
"""返回折扣金额(正值)"""
class FidelityPromo(Promotion): # 第一个具体策略
"""为积分为1000或以上的顾客提供5%折扣"""
def discount(self, order):
return order.total() * .05 if order.customer.fidelity >= 1000 else 0
class BulkItemPromo(Promotion): # 第二个具体策略
"""单个商品为20个或以上时提供10%折扣"""
def discount(self, order):
discount = 0
for item in order.cart:
if item.quantity >= 20:
discount += item.total() * .1
return discount
class LargeOrderPromo(Promotion): # 第三个具体策略
"""订单中的不同商品达到10个或以上时提供7%折扣"""
def discount(self, order):
distinct_items = {item.product for item in order.cart}
if len(distinct_items) >= 10:
return order.total() * .07
return 0
>>> joe = Customer('John Doe', 0)
>>> ann = Customer('Ann Smith', 1100)
>>> cart = [LineItem('banana', 4, .5),
... LineItem('apple', 10, 1.5),
... LineItem('watermellon', 5, 5.0)]
>>> Order(joe, cart, FidelityPromo())
<Order total: 42.00 due: 42.00>
>>> Order(ann, cart, FidelityPromo())
<Order total: 42.00 due: 39.90>
>>> banana_cart = [LineItem('banana', 30, .5),
... LineItem('apple', 10, 1.5)]
>>> Order(joe, banana_cart, BulkItemPromo())
<Order total: 30.00 due: 28.50>
>>> long_order = [LineItem(str(item_code), 1, 1.0)
... for item_code in range(10)]
>>> Order(joe, long_order, LargeOrderPromo())
<Order total: 10.00 due: 9.30>
>>> Order(joe, cart, LargeOrderPromo())
<Order total: 42.00 due: 42.00>
6.1.2 使用函数实现“策略”模式
Order 类和使用函数实现的折扣策略:
from collections import namedtuple
Customer = namedtuple('Customer', 'name fidelity')
class LineItem:
def __init__(self, product, quantity, price):
self.product = product
self.quantity = quantity
self.price = price
def total(self):
return self.price * self.quantity
class Order: # 上下文
def __init__(self, customer, cart, promotion=None):
self.customer = customer
self.cart = list(cart)
self.promotion = promotion
def total(self):
if not hasattr(self, '__total'):
self.__total = sum(item.total() for item in self.cart)
return self.__total
def due(self):
if self.promotion is None:
discount = 0
else:
discount = self.promotion(self)
return self.total() - discount
def __repr__(self):
fmt = '<Order total: {:.2f} due: {:.2f}>'
return fmt.format(self.total(), self.due())
def fidelity_promo(order):
"""为积分为1000或以上的顾客提供5%折扣"""
return order.total() * .05 if order.customer.fidelity >= 1000 else 0
def bulk_item_promo(order):
"""单个商品为20个或以上时提供10%折扣"""
discount = 0
for item in order.cart:
if item.quantity >= 20:
discount += item.total() * .1
return discount
def large_order_promo(order):
"""订单中的不同商品达到10个或以上时提供7%折扣"""
distinct_items = {item.product for item in order.cart}
if len(distinct_items) >= 10:
return order.total() * .07
return 0
>>> joe = Customer('John Doe', 0)
>>> ann = Customer('Ann Smith', 1100)
>>> cart = [LineItem('banana', 4, .5),
... LineItem('apple', 10, 1.5),
... LineItem('watermellon', 5, 5.0)]
>>> Order(joe, cart, fidelity_promo)
<Order total: 42.00 due: 42.00>
>>> Order(ann, cart, fidelity_promo)
<Order total: 42.00 due: 39.90>
>>> banana_cart = [LineItem('banana', 30, .5),
... LineItem('apple', 10, 1.5)]
>>> Order(joe, banana_cart, bulk_item_promo)
<Order total: 30.00 due: 28.50>
>>> long_order = [LineItem(str(item_code), 1, 1.0)
... for item_code in range(10)]
>>> Order(joe, long_order, large_order_promo)
<Order total: 10.00 due: 9.30>
>>> Order(joe, cart, large_order_promo)
<Order total: 42.00 due: 42.00>
在复杂的情况下,需要具体策略维护内部状态时,可能需要把“策略”和“享元”模式结合起来。但是,具体策略一般没有内部状态,只是处理上下文中的数据。此时,一定要使用普通的函数,别去编写只有一个方法的类,再去实现另一个类声明的单函数接口。函数比用户定义的类的实例轻量,而且无需使用“享元”模式,因为各个策略函数在 Python 编译模块时只会创建一次。普通的函数也是 “可共享的对象,可以同时在多个上下文中使用”。
6.1.3 选择最佳策略:简单的方式
promos = [fidelity_promo, bulk_item_promo, large_order_promo]
def best_promo(order):
"""选择可用的最佳折扣"""
return max(promo(order) for promo in promos)
6.1.4 找出模块中的全部策略
globals() 返回一个字典,表示当前的全局符号表。这个符号表始终针对当前模块(对函数或方法来说,是指定义它们的模块,而不是调用它们的模块)。
内省模块的全局命名空间,构建 promos 列表:
promos = [globals()[name] for name in globals()
if name.endswith('_promo')
and name != 'best_promo']
def best_promo(order):
"""选择可用的最佳折扣"""
return max(promo(order) for promo in promos)
收集所有可用促销的另一种方法是,在一个单独的模块中保存所有策略函数,把 best_promo 排除在外。
promos = [func for name, func in
inspect.getmembers(promotions, inspect.isfunction)]
def best_promo(order):
"""选择可用的最佳折扣"""
return max(promo(order) for promo in promos)
6.2 “命令”模式
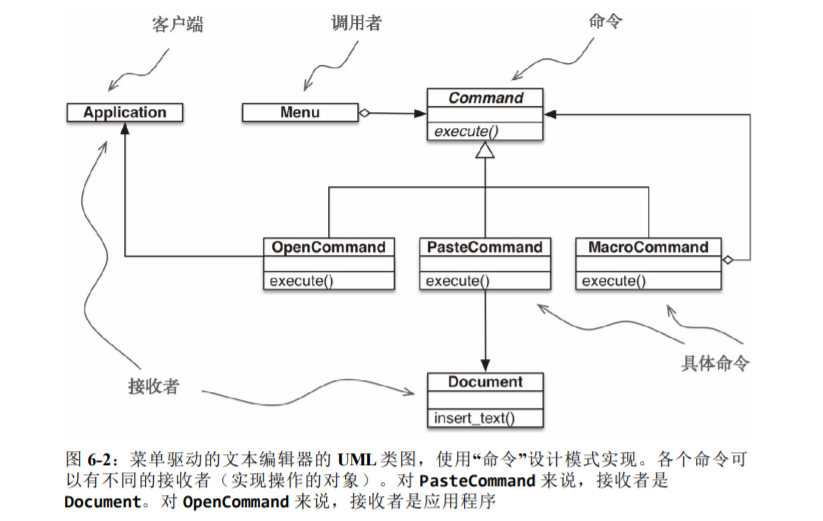
“命令”模式的目的是解耦调用操作的对象(调用者)和提供实现的对象(接收者)。在《设计模式:可复用面向对象软件的基础》所举的示例中,调用者是图形应用程序中的菜单项,而接收者是被编辑的文档或应用程序自身。
class MacroCommand:
"""一个执行一组命令的命令"""
def __init__(self, commands):
self.commands = list(commands)
def __call__(self):
for command in self.commands:
command()
使用一等函数对“命令”模式的重新审视到此结束。站在一定高度上看,这里采用的方式与“策略”模式所用的类似:把实现单方法接口的类的实例替换成可调用对象。 毕竟,每个Python 可调用对象都实现了单方法接口,这个方法就是 __call__。
7. 函数装饰器和闭包
函数装饰器用于在源码中“标记”函数,以某种方式增强函数的行为。这是一项强大的功能,但是若想掌握,必须理解闭包。
除了在装饰器中有用处之外,闭包还是回调式异步编程和函数式编程风格的基础。
7.1 装饰器基础知识
装饰器是可调用的对象,其参数是另一个函数(被装饰的函数)。装饰器可能会处理被装饰的函数,然后把它返回,或者将其替换成另一个函数或可调用对象。
@decorate def target():
def target(): ==> print('running target()')
print('running target()') target = decorate(target)
严格来说,装饰器只是语法糖。装饰器可以像常规的可调用对象那样调用,其参数是另一个函数。有时,这样做更方便,尤其是做元编程(在运行时改变程序的行为)时。
综上,装饰器的一大特性是,能把被装饰的函数替换成其他函数。第二个特性是,装饰器在加载模块时立即执行(在被装饰的函数定义之后立即运行。这通常是在导入时,即 Python 加载模块时)。
7.2 使用装饰器改进“策略”模式
promos = []
def promotion(promo_func):
promos.append(promo_func)
return promo_func
@promotion
def fidelity(order):
"""为积分为1000或以上的顾客提供5%折扣"""
return order.total() * .05 if order.customer.fidelity >= 1000 else 0
@promotion
def bulk_item(order):
"""单个商品为20个或以上时提供10%折扣"""
discount = 0
for item in order.cart:
if item.quantity >= 20:
discount += item.total() * .1
return discount
@promotion
def large_order(order):
"""订单中的不同商品达到10个或以上时提供7%折扣"""
distinct_items = {item.product for item in order.cart}
if len(distinct_items) >= 10:
return order.total() * .07
return 0
def best_promo(order):
"""选择可用的最佳折扣"""
return max(promo(order) for promo in promos)
7.3 变量作用域规则
Python 不要求声明变量,但是假定在函数定义体中赋值的变量是局部变量。如果在函数中赋值时想让解释器将其当成全局变量,要使用 global 声明。
7.4 闭包
闭包指延伸了作用域的函数,其中包含函数定义体中引用、但是不在定义体中定义的非全局变量。
def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total/len(series)
return averager
>>> avg = make_averager()
>>> avg(10)
10.0
>>> avg(11)
10.5
>>> avg(12)
11.0

在 averager 函数中,series 是自由变量(free variable)。审查返回的 averager 对象,我们发现 Python 在 __code__ 属性(表示编译后的函数定义
体)中保存局部变量和自由变量的名称:
>>> avg.__code__.co_varnames
('new_value', 'total')
>>> avg.__code__.co_freevars
('series',)
series 的绑定在返回的 avg 函数的 __closure__ 属性中。avg.__closure__ 中的各个元素对应于 avg.__code__.co_freevars 中的一个名称。这些元素是 cell 对象,有个 cell_contents 属性,保存着真正的值。
>>> avg.__code__.co_freevars
('series',)
>>> avg.__closure__
(<cell at 0x107a44f78: list object at 0x107a91a48>,)
>>> avg.__closure__[0].cell_contents
[10, 11, 12]
综上,闭包是一种函数,它会保留定义函数时存在的自由变量的绑定,这样调用函数时,
虽然定义作用域不可用了,但是仍能使用那些绑定。
注意,只有嵌套在其他函数中的函数才可能需要处理不在全局作用域中的外部变量。
7.5 nonlocal 声明
对数字、字符串、元组等不可变类型来说,只能读取,不能更新。如果尝试重新绑
定,例如 count = count + 1,其实会隐式创建局部变量 count。这样,count 就不是
自由变量了,因此不会保存在闭包中。
为了解决这个问题,Python 3 引入了 nonlocal 声明。它的作用是把变量标记为自由变量,即使在函数中为变量赋予新值了,也会变成自由变量。如果为 nonlocal 声明的变量赋予新值,闭包中保存的绑定会更新。
def make_averager():
count = 0
total = 0
def averager(new_value):
nonlocal count, total
count += 1
total += new_value
return total / count
return averager
7.6 实现一个简单的装饰器
import time
def clock(func):
def clocked(*args): # 定义内部函数 clocked,它接受任意个定位参数。
t0 = time.perf_counter()
result = func(*args) # clocked 的闭包中包含自由变量 func。
elapsed = time.perf_counter() - t0
name = func.__name__
arg_str = ', '.join(repr(arg) for arg in args)
print('[%0.8fs] %s(%s) -> %r' % (elapsed, name, arg_str, result))
return result
return clocked #返回内部函数,取代被装饰的函数。
# clockdeco_demo.py
import time
from clockdeco import clock
@clock
def snooze(seconds):
time.sleep(seconds)
@clock
def factorial(n):
return 1 if n < 2 else n*factorial(n-1)
if __name__=='__main__':
print('*' * 40, 'Calling snooze(.123)')
snooze(.123)
print('*' * 40, 'Calling factorial(6)')
print('6! =', factorial(6))
$ python3 clockdeco_demo.py
**************************************** Calling snooze(123)
[0.12405610s] snooze(.123) -> None
**************************************** Calling factorial(6)
[0.00000191s] factorial(1) -> 1
[0.00004911s] factorial(2) -> 2
[0.00008488s] factorial(3) -> 6
[0.00013208s] factorial(4) -> 24
[0.00019193s] factorial(5) -> 120
[0.00026107s] factorial(6) -> 720
6! = 72
这是装饰器的典型行为:把被装饰的函数替换成新函数,二者接受相同的参数,而且(通常)返回被装饰的函数本该返回的值,同时还会做些额外操作。
上面实现的 clock 装饰器有几个缺点:不支持关键字参数,而且遮盖了被装饰函
数的 __name__ 和 __doc__ 属性。下面使用 functools.wraps 装饰器把相关的属性从 func 复制到 clocked 中。此外,这个新版还能正确处理关键字参数。
# clockdeco2.py
import time
import functools
def clock(func):
@functools.wraps(func)
def clocked(*args, **kwargs):
t0 = time.time()
result = func(*args, **kwargs)
elapsed = time.time() - t0
name = func.__name__
arg_lst = []
if args:
arg_lst.append(', '.join(repr(arg) for arg in args))
if kwargs:
pairs = ['%s=%r' % (k, w) for k, w in sorted(kwargs.items())]
arg_lst.append(', '.join(pairs))
arg_str = ', '.join(arg_lst)
print('[%0.8fs] %s(%s) -> %r ' % (elapsed, name, arg_str, result))
return result
return clocked
7.7 标准库中的装饰器
Python 内置了三个用于装饰方法的函数:property、classmethod 和 staticmethod。另一个常见的装饰器是 functools.wraps,它的作用是协助构建行为良好的装饰器。标准库中最值得关注的两个装饰器是 lru_cache 和全新的
singledispatch(Python 3.4 新增)。这两个装饰器都在 functools 模块中定义。
7.7.1 使用 functools.lru_cache 做备忘
functools.lru_cache 是非常实用的装饰器,它实现了备忘(memoization)功能。这是一项优化技术,它把耗时的函数的结果保存起来,避免传入相同的参数时重复计算。LRU 三个字母是 Least Recently Used 的缩写,表明缓存不会无限制增长,一段时间不用的缓存条目会被扔掉。
import functools
from clockdeco import clock
@functools.lru_cache()
@clock
def fibonacci(n):
if n < 2:
return n
return fibonacci(n-2) + fibonacci(n-1)
if __name__=='__main__':
print(fibonacci(6))
$ python3 fibo_demo_lru.py
[0.00000119s] fibonacci(0) -> 0
[0.00000119s] fibonacci(1) -> 1
[0.00010800s] fibonacci(2) -> 1
[0.00000787s] fibonacci(3) -> 2
[0.00016093s] fibonacci(4) -> 3
[0.00001216s] fibonacci(5) -> 5
[0.00025296s] fibonacci(6) -> 8
maxsize 参数指定存储多少个调用的结果。缓存满了之后,旧的结果会被扔掉,腾出空
间。为了得到最佳性能,maxsize 应该设为 2 的幂。typed 参数如果设为 True,把不同参数类型得到的结果分开保存,即把通常认为相等的浮点数和整数参数(如 1 和 1.0)区分开。顺便说一下,因为 lru_cache 使用字典存储结果,而且键根据调用时传入的定位参数和关键字参数创建,所以被 lru_cache 装饰的函数,它的所有参数都必须是可散列的。
functools.lru_cache(maxsize=128, typed=False)
7.7.2 单分派泛函数
Python 3.4 新增的 functools.singledispatch 装饰器可以把整体方案拆分成多个模块,甚至可以为你无法修改的类提供专门的函数。使用 @singledispatch 装饰的普通函数会变成泛函数(generic function):根据第一个参数的类型,以不同方式执行相同操作的一组函数。
singledispatch 创建一个自定义的 htmlize.register 装饰器,把多个函数绑在一起组成一个泛函数:
from functools import singledispatch
from collections import abc
import numbers
import html
@singledispatch #@singledispatch 标记处理 object 类型的基函数
def htmlize(obj):
content = html.escape(repr(obj))
return '<pre>{}</pre>'.format(content)
@htmlize.register(str) #@«base_function».register(«type»)
def _(text):
content = html.escape(text).replace('\n', '<br>\n')
return '<p>{0}</p>'.format(content)
@htmlize.register(numbers.Integral)
def _(n):
return '<pre>{0} (0x{0:x})</pre>'.format(n)
@htmlize.register(tuple) #可以叠放多个 register 装饰器,让同一个函数支持不同类型
@htmlize.register(abc.MutableSequence)
def _(seq):
inner = '</li>\n<li>'.join(htmlize(item) for item in seq)
return '<ul>\n<li>' + inner + '</li>\n</ul>'
只要可能,注册的专门函数应该处理抽象基类(如 numbers.Integral 和 abc.MutableSequence),不要处理具体实现(如 int 和 list)。这样,代码支持的兼容类型更广泛。例如,Python 扩展可以子类化 numbers.Integral,使用固定的位数实现 int 类型。
singledispatch 机制的一个显著特征是,你可以在系统的任何地方和任何模块中注册专门函数。如果后来在新的模块中定义了新的类型,可以轻松地添加一个新的专门函数来处理那个类型。此外,你还可以为不是自己编写的或者不能修改的类添加自定义函数。
7.8 叠放装饰器
@d1
@d2
def f():
print('f')
等价于
def f():
print('f')
f = d1(d2(f))
7.9 参数化装饰器
解析源码中的装饰器时,Python 把被装饰的函数作为第一个参数传给装饰器函数。那怎么让装饰器接受其他参数呢?答案是:创建一个装饰器工厂函数,把参数传给它,返回一个装饰器,然后再把它应用到要装饰的函数上。
一个参数化的注册装饰器:
registry = set()
def register(active=True):
def decorate(func):
print('running register(active=%s)->decorate(%s)' % (active, func))
if active:
registry.add(func)
else:
registry.discard(func)
return func
return decorate
@register(active=False)
def f1():
print('running f1()')
@register()
def f2():
print('running f2()')
def f3():
print('running f3()')
如果不使用 @ 句法,那就要像常规函数那样使用 register;若想把 f 添加到 registry 中,则装饰 f 函数的句法是 register()(f);不想添加(或把它删除)的话,句法是 register(active=False)(f)。
参数化 clock 装饰器:
import time
DEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}'
def clock(fmt=DEFAULT_FMT):
def decorate(func):
def clocked(*_args):
t0 = time.time()
_result = func(*_args)
elapsed = time.time() - t0
name = func.__name__
args = ', '.join(repr(arg) for arg in _args)
result = repr(_result)
print(fmt.format(**locals())) # **locals() 是为了在 fmt 中引用 clocked 的局部变量
return _result
return clocked
return decorate
if __name__ == '__main__':
@clock()
def snooze(seconds):
time.sleep(seconds)
for i in range(3):
snooze(.123)
8. 对象引用、可变性和垃圾回收
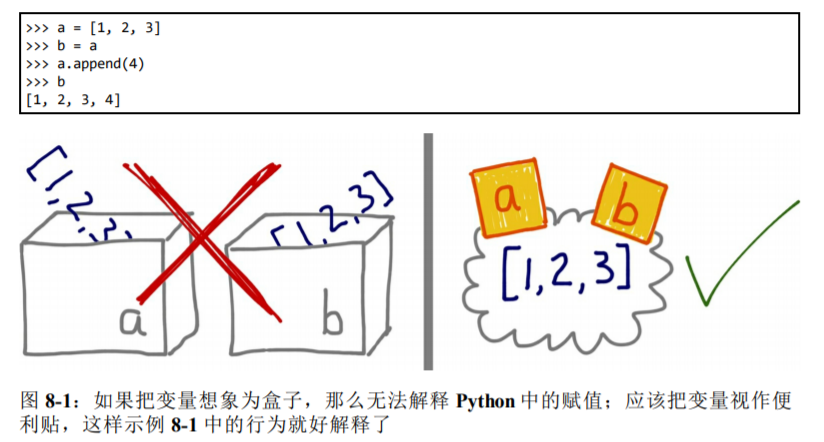
8.1 变量不是盒子
Python 变量类似于 Java 中的引用式变量,因此最好把它们理解为附加在对象上的标注。
为了理解 Python 中的赋值语句,应该始终先读右边。对象在右边创建或获取(把变量 s 分配给 seesaw),在此之后左边的变量才会绑定到对象上,这就像为对象贴上标注。忘掉盒子吧!
8.2 标识、相等性和别名
每个变量都有标识、类型和值。对象一旦创建,它的标识绝不会变;你可以把标识理解为对象在内存中的地址。is 运算符比较两个对象的标识;id() 函数返回对象标识的整数表示。
对象 ID 的真正意义在不同的实现中有所不同。在 CPython 中,id() 返回对象的内存地址,但是在其他 Python 解释器中可能是别的值。关键是,ID 一定是唯一的数值标注,而且在对象的生命周期中绝不会变。
8.2.1 在==和is之间选择
== 运算符比较两个对象的值(对象中保存的数据),而 is 比较对象的标识。
通常,我们关注的是值,而不是标识,因此 Python 代码中 == 出现的频率比 is 高。
然而,在变量和单例值之间比较时,应该使用 is。目前,最常使用 is 检查变量绑定的值是不是 None。下面是推荐的写法:
x is None / x is not None
8.2.2 元组的相对不可变性
元组与多数 Python 集合(列表、字典、集,等等)一样,保存的是对象的引用。 如果引用的元素是可变的(而 str、bytes 和 array.array 等单一类型序列是扁平的,它们保存的不是引用,而是在连续的内存中保存数据本身<字符、字节和数字>。),即便元组本身不可变,元素依然可变。也就是说,元组的不可变性其实是指 tuple 数据结构的物理内容(即保存的引用)不可变,与引用的对象无关。
>>> t2 = (1, 2, [30, 40])
>>> t1 == t2
True
>>> id(t1[-1])
4302515784
>>> t1[-1].append(99)
>>> t1
(1, 2, [30, 40, 99])
>>> id(t1[-1])
4302515784
>>> t1 == t2
False
8.3 默认做浅复制
复制列表(或多数内置的可变集合)最简单的方式是使用内置的类型构造方法。
>>> l1 = [3, [55, 44], (7, 8, 9)]
>>> l2 = list(l1)
>>> l2
[3, [55, 44], (7, 8, 9)]
>>> l2 == l1
True
>>> l2 is l1
False
然而,构造方法或 [:] 做的是浅复制(即复制了最外层容器,副本中的元素是源容器中元素的引用)。如果所有元素都是不可变的,那么这样没有问题,还能节省内存。但是,如果有可变的元素,可能就会导致意想不到的问题。
浅复制没什么问题,但有时我们需要的是深复制(即副本不共享内部对象的引用)。copy 模块提供的 deepcopy 和 copy 函数能为任意对象做深复制和浅复制。
class Bus:
def __init__(self, passengers=None):
if passengers is None:
self.passengers = []
else:
self.passengers = list(passengers)
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name)
>>> import copy
>>> bus1 = Bus(['Alice', 'Bill', 'Claire', 'David'])
>>> bus2 = copy.copy(bus1)
>>> bus3 = copy.deepcopy(bus1)
>>> id(bus1), id(bus2), id(bus3)
(4301498296, 4301499416, 4301499752)
>>> bus1.drop('Bill')
>>> bus2.passengers
['Alice', 'Claire', 'David']
>>> id(bus1.passengers), id(bus2.passengers), id(bus3.passengers)
(4302658568, 4302658568, 4302657800)
>>> bus3.passengers
['Alice', 'Bill', 'Claire', 'David']
注意,一般来说,深复制不是件简单的事。如果对象有循环引用,那么这个朴素的算法会进入无限循环。deepcopy 函数会记住已经复制的对象,因此能优雅地处理循环引用:
>>> a = [10, 20]
>>> b = [a, 30]
>>> a.append(b)
>>> a
[10, 20, [[...], 30]]
>>> from copy import deepcopy
>>> c = deepcopy(a)
>>> c
[10, 20, [[...], 30]]
此外,深复制有时可能太深了。例如,对象可能会引用不该复制的外部资源或单例值。我们可以实现特殊方法 __copy__() 和 __deepcopy__(),控制 copy 和 deepcopy 的行为.
8.4 函数的参数作为引用时
Python 唯一支持的参数传递模式是共享传参(call by sharing)。多数面向对象语言都采用这一模式,包括 Ruby、Smalltalk 和 Java(Java 的引用类型是这样,基本类型按值传参)。
共享传参指函数的各个形式参数获得实参中各个引用的副本。也就是说,函数内部的形参是实参的别名。
这种方案的结果是,函数可能会修改作为参数传入的可变对象,但是无法修改那些对象的标识(即不能把一个对象替换成另一个对象)。示例 8-11 中有个简单的函数,它在参数上调用 += 运算符。分别把数字、列表和元组传给那个函数,实际传入的实参会以不同的方式受到影响。
>>> def f(a, b):
... a += b
... return a
...
>>> x = 1
>>> y = 2
>>> f(x, y)
3
>>> x, y
(1, 2) #数字 x 没变
>>> a = [1, 2]
>>> b = [3, 4]
>>> f(a, b)
[1, 2, 3, 4]
>>> a, b #列表 a 变了
([1, 2, 3, 4], [3, 4])
>>> t = (10, 20)
>>> u = (30, 40)
>>> f(t, u)
(10, 20, 30, 40)
>>> t, u #元组 t 没变
((10, 20), (30, 40))
8.4.1 不要使用可变类型作为参数的默认值
class HauntedBus:
"""备受幽灵乘客折磨的校车"""
def __init__(self, passengers=[]): ➊
self.passengers = passengers ➋
def pick(self, name):
self.passengers.append(name) ➌
def drop(self, name):
self.passengers.remove(name)
>>> bus1 = HauntedBus(['Alice', 'Bill'])
>>> bus1.passengers
['Alice', 'Bill']
>>> bus1.pick('Charlie')
>>> bus1.drop('Alice')
>>> bus1.passengers
['Bill', 'Charlie']
>>> bus2 = HauntedBus()
>>> bus2.pick('Carrie')
>>> bus2.passengers
['Carrie']
>>> bus3 = HauntedBus()
>>> bus3.passengers
['Carrie']
>>> bus3.pick('Dave')
>>> bus2.passengers
['Carrie', 'Dave']
>>> bus2.passengers is bus3.passengers
True
>>> bus1.passengers
['Bill', 'Charlie']
默认值在定义函数时计算(通常在加载模块时),因此默认值变成了函数对象的属性。因此,如果默认值是可变对象,而且修改了它的值,那么后续的函数调用都会受到影响。
>>> dir(HauntedBus.__init__) # doctest: +ELLIPSIS
['__annotations__', '__call__', ..., '__defaults__', ...]
>>> HauntedBus.__init__.__defaults__
(['Carrie', 'Dave'],
>>> HauntedBus.__init__.__defaults__[0] is bus2.passengers
True
8.4.2 防御可变参数
class TwilightBus:
"""让乘客销声匿迹的校车"""
def __init__(self, passengers=None):
if passengers is None:
self.passengers = [] #当 passengers 为 None 时,创建一个新的空列表
else:
self.passengers = passengers #这个赋值语句把 self.passengers 变成 passengers 的别名,而后者是传给__init__ 方法的实参
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name) #在 self.passengers 上调用 .remove() 和 .append() 方法其实会修改传给构造方法的那个列表
这里的问题是,校车为传给构造方法的列表创建了别名。正确的做法是,校车自己维护乘客列表。修正的方法很简单:在 __init__ 中,传入 passengers 参数时,应该把参数值的副本赋值给 self.passengers:
def __init__(self, passengers=None):
if passengers is None:
self.passengers = []
else:
self.passengers = list(passengers)
除非这个方法确实想修改通过参数传入的对象,否则在类中直接把参数赋值给实例变量之前一定要三思,因为这样会为参数对象创建别名。如果不确定,那就创建副本。这样客户会少些麻烦。
8.5 del 和 垃圾回收
对象绝不会自行销毁;然而,无法得到对象时,可能会被当作垃圾回收。
del 语句删除名称,而不是对象。del 命令可能会导致对象被当作垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用,或者无法得到对象时。 重新绑定也可能会导致对象的引用数量归零,导致对象被销毁。
在 CPython 中,垃圾回收使用的主要算法是引用计数。实际上,每个对象都会统计有多少引用指向自己。当引用计数归零时,对象立即就被销毁:CPython 会在对象上调用 __del__ 方法(如果定义了),然后释放分配给对象的内存。CPython 2.0 增加了分代垃圾回收算法,用于检测引用循环中涉及的对象组——如果一组对象之间全是相互引用,即使再出色的引用方式也会导致组中的对象不可获取。Python 的其他实现有更复杂的垃圾回收程序,而且不依赖引用计数,这意味着,对象的引用数量为零时可能不会立即调用 __del__ 方法。
没有指向对象的引用时,监视对象生命结束时的情形:
>>> import weakref
>>> s1 = {1, 2, 3}
>>> s2 = s1
>>> def bye():
... print('Gone with the wind...')
...
>>> ender = weakref.finalize(s1, bye) # finalize 持有 {1, 2, 3} 的弱引用
>>> ender.alive
True
>>> del s1
>>> ender.alive
True
>>> s2 = 'spam'
Gone with the wind...
>>> ender.alive
False
8.6 弱引用
正是因为有引用,对象才会在内存中存在。当对象的引用数量归零后,垃圾回收程序会把对象销毁。但是,有时需要引用对象,而不让对象存在的时间超过所需时间。这经常用在缓存中。
弱引用不会增加对象的引用数量。引用的目标对象称为所指对象(referent)。因此我们说,弱引用不会妨碍所指对象被当作垃圾回收。
弱引用在缓存应用中很有用,因为我们不想仅因为被缓存引用着而始终保存缓存对象。
弱引用是可调用的对象,返回的是被引用的对象;如果所指对象不存在
了,返回 None:
>>> import weakref
>>> a_set = {0, 1}
>>> wref = weakref.ref(a_set)
>>> wref
<weakref at 0x100637598; to 'set' at 0x100636748>
>>> wref()
{0, 1}
>>> a_set = {2, 3, 4}
>>> wref()
{0, 1}
>>> wref() is None
False
>>> wref() is None
True
weakref 模块的文档(http://docs.python.org/3/library/weakref.html )指出,weakref.ref 类其实是低层接口,供高级用途使用,多数程序最好使用 weakref 集合和 finalize。也 就是说,应该使用 WeakKeyDictionary、WeakValueDictionary、WeakSet 和 finalize(在内部使用弱引用),不要自己动手创建并处理 weakref.ref 实例。
8.6.1 WeakValueDictionary
WeakValueDictionary 类实现的是一种可变映射,里面的值是对象的弱引用。被引用的对象在程序中的其他地方被当作垃圾回收后,对应的键会自动从 WeakValueDictionary 中删除。因此,WeakValueDictionary 经常用于缓存。
class Cheese:
def __init__(self, kind):
self.kind = kind
def __repr__(self):
return 'Cheese(%r)' % self.kind
>>> import weakref
>>> stock = weakref.WeakValueDictionary() ➊
>>> catalog = [Cheese('Red Leicester'), Cheese('Tilsit'),
... Cheese('Brie'), Cheese('Parmesan')]
...
>>> for cheese in catalog:
... stock[cheese.kind] = cheese ➋
...
>>> sorted(stock.keys())
['Brie', 'Parmesan', 'Red Leicester', 'Tilsit'] ➌
>>> del catalog
>>> sorted(stock.keys())
['Parmesan'] ➍
>>> del cheese
>>> sorted(stock.keys())
[]
临时变量引用了对象,这可能会导致该变量的存在时间比预期长。通常,这对
局部变量来说不是问题,因为它们在函数返回时会被销毁。但是在上面的示例中,for 循环中的变量 cheese 是全局变量,除非显式删除,否则不会消失。
与 WeakValueDictionary 对应的是 WeakKeyDictionary,后者的键是弱引
用。WeakKeyDictionary 实例可以为应用中其他部分拥有的对象附加数据,这样就无需为对象添加属性。这对覆盖属性访问权限的对象尤其有用。
weakref 模块还提供了 WeakSet 类,按照文档的说明,这个类的作用很简单:“保存元素弱引用的集合类。元素没有强引用时,集合会把它删除。”如果一个类需要知道所有实例,一种好的方案是创建一个 WeakSet 类型的类属性,保存实例的引用。如果使用常规的 set,实例永远不会被垃圾回收,因为类中有实例的强引用,而类存在的时间与 Python 进程一样长,除非显式删除类。
8.6.2 弱引用的局限
不是每个 Python 对象都可以作为弱引用的目标(或称所指对象)。基本的 list 和 dict 实例不能作为所指对象,但是它们的子类可以轻松地解决这个问题:
class MyList(list):
"""list的子类,实例可以作为弱引用的目标"""
a_list = MyList(range(10))
# a_list可以作为弱引用的目标
wref_to_a_list = weakref.ref(a_list)
set 实例可以作为所指对象,用户定义的类型也没问题,但是,int 和 tuple 实例不能作为弱引用的目标,甚至它们的子类也不行。
8.7 Python 对不可变类型施加的把戏
对元组 t 来说,t[:] 不创建副本,而是返回同一个对象的引用。此
外,tuple(t) 获得的也是同一个元组的引用。
文档明确指出了这个行为。在 Python 控制台中输入 help(tuple),你会看到这句话:“如果参数是一个元组,那么返回值是同一个对象。”
str、bytes 和 frozenset 实例也有这种行为。注意,frozenset 实例不是序列,因此不能使用 fs[:](fs 是一个 frozenset 实例)。但是,fs.copy() 具有相同的效果:它会欺骗你,返回同一个对象的引用,而不是创建一个副本。
共享字符串字面量是一种优化措施,称为驻留(interning)。CPython 还会在小的整数上使用这个优化措施,防止重复创建“热门”数字,如 0、-1 和 42。注意,CPython 不会驻留所有字符串和整数,驻留的条件是实现细节,而且没有文档说明。
8.8 Summary
每个 Python 对象都有标识、类型和值。只有对象的值会不时变化。
变量保存的是引用,这一点对 Python 编程有很多实际的影响。
-
简单的赋值不创建副本。
-
对 += 或 *= 所做的增量赋值来说,如果左边的变量绑定的是不可变对象,会创建新对象;如果是可变对象,会就地修改。
-
为现有的变量赋予新值,不会修改之前绑定的变量。这叫重新绑定:现在变量绑定了其他对象。如果变量是之前那个对象的最后一个引用,对象会被当作垃圾回收。
-
函数的参数以别名的形式传递,这意味着,函数可能会修改通过参数传入的可变对象。这一行为无法避免,除非在本地创建副本,或者使用不可变对象(例如,传入元组,而不传入列表)。
-
使用可变类型作为函数参数的默认值有危险,因为如果就地修改了参数,默认值也就变了,这会影响以后使用默认值的调用。
在 CPython 中,对象的引用数量归零后,对象会被立即销毁。如果除了循环引用之外没有其他引用,两个对象都会被销毁。某些情况下,可能需要保存对象的引用,但不留存对象本身。例如,有一个类想要记录所有实例。这个需求可以使用弱引用实现,这是一种低层机制,是 weakref 模块中 WeakValueDictionary、WeakKeyDictionary 和 WeakSet 等有用的集合类,以及 finalize 函数的底层支持。
9. 符合 Python 风格的对象
9.1 对象的表示形式
-
repr()以便于开发者理解的方式返回对象的字符串表示形式。 -
str()以便于用户理解的方式返回对象的字符串表示形式。
9.2 再谈向量类
Vector2d 实例有多种表示形式:
from array import array
import math
class Vector2d:
typecode = 'd'
def __init__(self, x, y):
self.x = float(x)
self.y = float(y)
def __iter__(self): #可迭代对象
return (i for i in (self.x, self.y))
def __repr__(self):
class_name = type(self).__name__
return '{}({!r}, {!r})'.format(class_name, *self)
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) + bytes(array(self.typecode, self)))
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
return math.hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
>>> v1 = Vector2d(3, 4)
>>> print(v1.x, v1.y)
3.0 4.0
>>> x, y = v1
>>> x, y
(3.0, 4.0)
>>> v1
Vector2d(3.0, 4.0)
>>> v1_clone = eval(repr(v1))
>>> v1 == v1_clone
True
>>> print(v1)
(3.0, 4.0)
>>> octets = bytes(v1)
>>> octets
b'd\\x00\\x00\\x00\\x00\\x00\\x00\\x08@\\x00\\x00\\x00\\x00\\x00\\x00\\x10@'
>>> abs(v1)
5.0
>>> bool(v1), bool(Vector2d(0, 0))
9.3 备选构造方法
使用 bytes() 函数生成的二进制表示形式重建 Vector2d 实例:
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(*memv)
9.4 classmethod 与 staticmethod
classmethod 定义操作类,而不是操作实例的方法。。classmethod 改变了调用方法的方式,因此类方法的第一个参数是类本身,而不是实例 classmethod 最常见的用途是定义备选构造方法。
staticmethod 装饰器也会改变方法的调用方式,但是第一个参数不是特殊的值。其实,静态方法就是普通的函数,只是碰巧在类的定义体中,而不是在模块层定义。
比较 classmethod 和 staticmethod 的行为:
>>> class Demo:
... @classmethod
... def klassmeth(*args):
... return args
... @staticmethod
... def statmeth(*args):
... return args
...
>>> Demo.klassmeth() # 不管怎样调用 Demo.klassmeth,它的第一个参数始终是 Demo 类。
(<class '__main__.Demo'>,)
>>> Demo.klassmeth('spam')
(<class '__main__.Demo'>, 'spam')
>>> Demo.statmeth() # Demo.statmeth 的行为与普通的函数相似。
()
>>> Demo.statmeth('spam')
('spam',)
9.5 格式化显示
内置的 format() 函数和 str.format() 方法把各个类型的格式化方式委托给相应的 .__format__(format_spec) 方法。format_spec 是格式说明符,它是:
- format(my_obj, format_spec) 的第二个参数,或者
- str.format() 方法的格式字符串,
{}里代换字段中冒号后面的部分
>>> brl = 1/2.43 # BRL到USD的货币兑换比价
>>> brl
0.4115226337448559
>>> format(brl, '0.4f')
'0.4115'
>>> '1 BRL = {rate:0.2f} USD'.format(rate=brl) # ➋
'1 BRL = 0.41 USD'
在 Vector2d 类中定义:
def __format__(self, fmt_spec=''):
components = (format(c, fmt_spec) for c in self)
return '({}, {})'.format(*components)
为自定义的格式代码选择字母时,我会避免使用其他类型用过的字母。在 格式规范微语言 中我们看到,整数使用的代码有 bcdoxXn,浮点数使用的代码有 eEfFgGn%,字符串使用的代码有 s。因此,我为极坐标选的代码是 p。各个类使用自己的方式解释格式代码,在自定义的格式代码中重复使用代码字母不会出错,但是可能会让用户困惑。
def angle(self): # 计算角度
return math.atan2(self.y, self.x)
def __format__(self, fmt_spec=''):
if fmt_spec.endswith('p'):
fmt_spec = fmt_spec[:-1]
coords = (abs(self), self.angle())
outer_fmt = '<{}, {}>'
else:
coords = self
outer_fmt = '({}, {})'
components = (format(c, fmt_spec) for c in coords)
return outer_fmt.format(*components)
>>> format(Vector2d(1, 1), 'p')
'<1.4142135623730951, 0.7853981633974483>'
>>> format(Vector2d(1, 1), '.3ep')
'<1.414e+00, 7.854e-01>'
>>> format(Vector2d(1, 1), '0.5fp')
'<1.41421, 0.78540>'
9.6 可散列的 Vector2d
属性只读:
class Vector2d:
typecode = 'd'
def __init__(self, x, y):
self.__x = float(x) # 用两个前导下划线,标记属性为私有,名称改写(name mangling)
self.__y = float(y)
@property
def x(self):
return self.__x
@property
def y(self):
return self.__y
实现 __hash__ 方法:
def __hash__(self):
return hash(self.x) ^ hash(self.y)
要想创建可散列的类型,不一定要实现特性,也不一定要保护实例属性。只需正确地实现 __hash__ 和 __eq__ 方法即可。但是,实例的散列值绝不应该变化,因此我们借机提到了只读特性。
9.7 使用 __slots__ 类属性节省空间
默认情况下,Python 在各个实例中名为 __dict__ 的字典里存储实例属性。为了使用底层的散列表提升访问速度,字典会消耗大量内存。如果要处理数百万个属性不多的实例,通过 __slots__ 类属性,能节省大量内存,方法是让解释器在元组中存储实例属性,而不用字典。
class Vector2d:
__slots__ = ('__x', '__y')
typecode = 'd'
[...]
在类中定义 __slots__ 属性的目的是告诉解释器:“这个类中的所有实例属性都在这儿了!”这样,Python 会在各个实例中使用类似元组的结构存储实例变量,从而避免使用消耗内存的 __dict__ 属性。如果有数百万个实例同时活动,这样做能节省大量内存。
__slots__ 的问题:
-
每个子类都要定义
__slots__属性,因为解释器会忽略继承的__slots__属性。 -
实例只能拥有
__slots__中列出的属性,除非把__dict__加入__slots__中(这样做就失去了节省内存的功效)。 -
如果不把
__weakref__加入__slots__,实例就不能作为弱引用的目标。
10 序列的修改、散列和切片
序列协议:__len__ + __getitem__
迭代协议:__getitem__
from array import array
import reprlib
import math
class Vector:
typecode = 'd'
def __init__(self, components):
self._components = array(self.typecode, components)
def __iter__(self):
return iter(self._components)
def __repr__(self):
components = reprlib.repr(self._components)
components = components[components.find('['):-1]
return 'Vector({})'.format(components)
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) + bytes(self._components))
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
return math.sqrt(sum(x * x for x in self))
def __bool__(self):
return bool(abs(self))
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(memv)
10.1 能处理切片的 __getitem__ 方法
def __len__(self):
return len(self._components)
def __getitem__(self, index):
cls = type(self)
if isinstance(index, slice):
return cls(self._components[index])
elif isinstance(index, numbers.Integral):
return self._components[index]
else:
msg = '{cls.__name__} indices must be integers'
raise TypeError(msg.format(cls=cls))
10.2 动态存取特性
属性查找失败后,解释器会调用 __getattr__ 方法。简单来说,对 my_obj.x 表达式,Python 会检查 my_obj 实例有没有名为 x 的属性;如果没有,到类(my_obj.__class__)中查找;如果还没有,顺着继承树继续查找。 如果依旧找不到,调用 my_obj 所属类中定义的 __getattr__ 方法,传入 self 和属性名称的字符串形式。
shortcut_names = 'xyzt'
def __getattr__(self, name):
cls = type(self)
if len(name) == 1:
pos = cls.shortcut_names.find(name)
if 0 <= pos < len(self._components):
return self._components[pos]
msg = '{.__name__!r} object has no attribute {!r}'
raise AttributeError(msg.format(cls, name))
def __setattr__(self, name, value):
cls = type(self)
if len(name) == 1:
if name in cls.shortcut_names:
error = 'readonly attribute {attr_name!r}'
elif name.islower():
error = "can't set attributes 'a' to 'z' in {cls_name!r}"
else:
error = ''
if error:
msg = error.format(cls_name=cls.__name__, attr_name=name)
raise AttributeError(msg)
super().__setattr__(name, value)
10.3 散列和快速等值测试
def __hash__(self):
hashes = map(hash, self._components)
return functools.reduce(operator.xor, hashes)
def __eq__(self, other):
return len(self) == len(other) and all(a == b for a, b in zip(self, other))
10.4 格式化
def angle(self, n):
r = math.sqrt(sum(x * x for x in self[n:]))
a = math.atan2(r, self[n-1])
if (n == len(self) - 1) and (self[-1] < 0):
return math.pi * 2 - a
else:
return a
def angles(self):
return (self.angle(n) for n in range(1, len(self)))
def __format__(self, fmt_spec=''):
if fmt_spec.endswith('h'): # 超球面坐标
fmt_spec = fmt_spec[:-1]
coords = itertools.chain([abs(self)], self.angles())
outer_fmt = '<{}>' # <r, Φ1, Φ2, Φ3>
else:
coords = self
outer_fmt = '({})'
components = (format(c, fmt_spec) for c in coords)
return outer_fmt.format(', '.join(components))
11 接口:从协议到抽象基类
鸭子类型:对象的类型无关紧要,只要实现了特定的协议即可。忽略对象的真正类型,转而关注对象有没有实现所需的方法、签名和语义。
除了抽象基类,每个类都有接口:
-
类实现或继承的公开属性(方法或数据属性),包括特殊方法,如 __getitem__ 或 __add__。
-
对象公开方法的子集,让对象在系统中扮演特定的角色。接口是实现特定角色的方法集合。
Python 喜欢序列,鉴于序列协议的重要性,如果没有 __iter__ 和 __contains__ 方法,Python 会调用 __getitem__ 方法,设法让迭代和 in 运算符可用。
猴子补丁:在运行时修改类或模块,而不改动源码。猴子补丁很强大,但是打补丁的代码与要打补丁的程序耦合十分紧密,而且往往要处理隐藏和没有文档的部分。
Python 3.4 在 collections.abc 模块中定义了 16 个抽象基类:
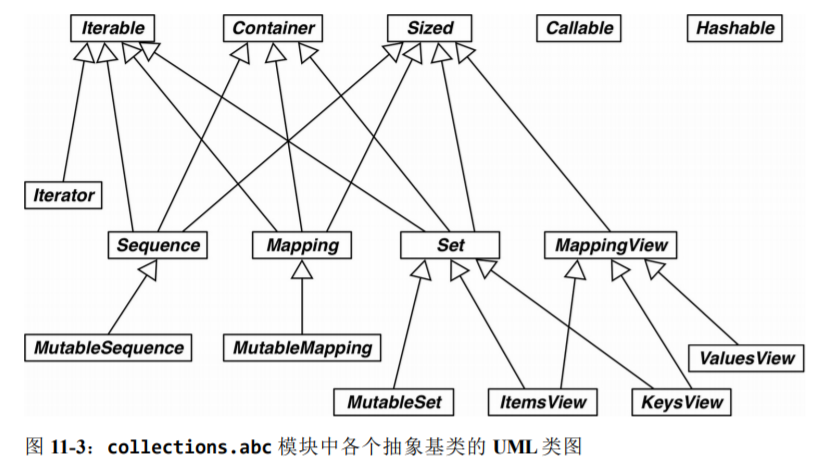
-
Iterable、Container 和 Sized
各个集合应该继承这三个抽象基类,或者至少实现兼容的协议。Iterable 通过
__iter__方法支持迭代,Container 通过__contains__方法支持 in 运算符,Sized通过__len__方法支持 len() 函数。 -
Sequence、Mapping 和 Set
这三个是主要的不可变集合类型,而且各自都有可变的子类。
-
MappingView
在 Python 3 中,映射方法 .items()、.keys() 和 .values() 返回的对象分别是 ItemsView、KeysView 和 ValuesView 的实例。前两个类还从 Set 类继承了丰富的接口,包含 3.8.3 节所述的全部运算符。
抽象基类的数字塔: numbers 定义的是“数字塔”(即各个抽象基类的层次结构是线性的),其中 Number 是位于最顶端的超类,随后是 Complex 子类,依次往下,最底端是 Integral 类:
- Number
- Complex
- Real
- Rational
- Integral
isinstance(x,numbers.Integral) # 判断 int bool(int 子类)
isinstance(x, numbers.Real) # 判断浮点数 bool、int、float、fractions.Fraction
14 可迭代的对象、迭代器和生成器
14.1 迭代器 & 生成器
序列可以迭代的原因:iter 函数。 解释器需要迭代对象 x 时,会自动调用 iter(x)。内置的 iter 函数有以下作用:
-
检查对象是否实现了
__iter__方法,如果实现了就调用它,获取一个迭代器。 -
如果没有实现
__iter__方法,但是实现了__getitem__方法,Python 会创建一个迭代器,尝试按顺序(从索引 0 开始)获取元素。 -
如果尝试失败,Python 抛出 TypeError 异常,通常会提示“C object is not iterable”(C 对象不可迭代),其中 C 是目标对象所属的类。
从 Python 3.4 开始,检查对象 x 能否迭代,最准确的方法是:调用 iter(x) 函数,如果不可迭代,再处理 TypeError 异常。这比使用 isinstance(x,
abc.Iterable) 更准确,因为 iter(x) 函数会考虑到遗留的 __getitem__ 方法,而 abc.Iterable 类则不考虑。
可迭代的对象:使用 iter 内置函数可以获取迭代器的对象。如果对象实现了能返回迭代器的 __iter__ 方法,那么对象就是可迭代的。序列都可以迭代;实现了 __getitem__ 方法,而且其参数是从零开始的索引,这种对象也可以迭代。Python 从可迭代的对象中获取迭代器。
迭代器:迭代器是这样的对象:实现了无参数的 __next__ 方法,返回序列中的下一个元素;如果没有元素了,那么抛出 StopIteration 异常。Python 中的迭代器还实现了 __iter__ 方法,因此迭代器也可以迭代。
标准的迭代器接口有两个方法:
-
__next__返回下一个可用的元素,如果没有元素了,抛出 StopIteration 异常。 -
__iter__返回 self,以便在应该使用可迭代对象的地方使用迭代器,例如在 for 循环中。
检查对象 x 是否为迭代器最好的方式是调用 isinstance(x, abc.Iterator)。得益于 Iterator.__subclasshook__ 方法,即使对象 x 所属的类不是 Iterator 类的真实子类或虚拟子类,也能这样检查。
迭代器可以迭代,但是可迭代的对象不是迭代器。
迭代器模式可用来:
- 访问一个聚合对象的内容而无需暴露它的内部表示
- 支持对聚合对象的多种遍历
- 为遍历不同的聚合结构提供一个统一的接口(即支持多态迭代)
生成器函数会创建一个生成器对象,包装生成器函数的定义体。把生成器传给 next(...) 函数时,生成器函数会向前,执行函数定义体中的下一个 yield 语句,返回产出的值,并在函数定义体的当前位置暂停。最终,函数的定义体返回时,外层的生成器对象会抛出 StopIteration 异常——这一点与迭代器协议一致。
for c in gen_AB(): 迭代时,for 机制的作用与 g = iter(gen_AB()) 一样,用于获取生成器对象,然后每次迭代时调用 next(g)。
惰性实现 + 生成器函数:
import re
import reprlib
RE_WORD = re.compile('\w+')
class Sentence:
def __init__(self, text):
self.text = text
def __repr__(self):
return 'Sentence(%s)' % reprlib.repr(self.text)
def __iter__(self):
for match in RE_WORD.finditer(self.text):
yield match.group()
=> g = iter(RE_WORD.finditer(self.text)), return next(g).group()
惰性实现 + 生成器表达式:
def __iter__(self):
return (match.group() for match in RE_WORD.finditer(self.text))
14.2 标准库中的生成器函数
14.2.1 用于过滤的生成器函数
| 模块 | 函数 | 说明 |
|---|---|---|
| itertools | compress(it, selector_it) | 并行处理两个可迭代的对象;如果 selector_it 中的元素是真值,产出 it 中对应的元素 |
| itertools | dropwhile(predicate, it) | 处理 it,跳过 predicate 的计算结果为真值的元素,然后产出剩下的各个元素(不再进一步检查) |
| (内置) | filter(predicate, it) | 把 it 中的各个元素传给 predicate,如果 predicate(item) 返回真值,那么产出对应的元素;如果 predicate 是 None,那么只产出真值元素 |
| itertools | filterfalse(predicate, it) | 与 filter 函数的作用类似,不过 predicate 的逻辑是相反的:predicate 返回假值时产出对应的元素 |
| itertools | islice(it, stop) 或 islice(it, start, stop, step=1) | 产出 it 的切片,作用类似于 s[:stop] 或 s[start:stop:step],不过 it 可以是任何可迭代的对象,而且这个函数实现的是惰性操作 |
| itertools | takewhile(predicate, it) | predicate 返回真值时产出对应的元素,然后立即停止,不再继续检查 |
>>> def vowel(c):
... return c.lower() in 'aeiou'
...
>>> list(filter(vowel, 'Aardvark'))
['A', 'a', 'a']
>>> import itertools
>>> list(itertools.filterfalse(vowel, 'Aardvark'))
['r', 'd', 'v', 'r', 'k']
>>> list(itertools.dropwhile(vowel, 'Aardvark'))
['r', 'd', 'v', 'a', 'r', 'k']
>>> list(itertools.takewhile(vowel, 'Aardvark'))
['A', 'a']
>>> list(itertools.compress('Aardvark', (1,0,1,1,0,1)))
['A', 'r', 'd', 'a']
>>> list(itertools.islice('Aardvark', 4))
['A', 'a', 'r', 'd']
>>> list(itertools.islice('Aardvark', 4, 7))
['v', 'a', 'r']
>>> list(itertools.islice('Aardvark', 1, 7, 2))
['a', 'd', 'a']
14.2.2 用于映射的生成器函数
| 模块 | 函数 | 说明 |
|---|---|---|
| itertools | accumulate(it,[func]) | 产出累积的总和;如果提供了 func,那么把前两个元素传给它,然后把计算结果和下一个元素传给它,以此类推,最后产出结果 |
| (内置) | enumerate(iterable, start=0) | 产出由两个元素组成的元组,结构是 (index, item),其中 index 从 start 开始计数,item 则从 iterable 中获取 |
| (内置) | map(func, it1,[it2, ..., itN]) | 把 it 中的各个元素传给func,产出结果;如果传入 N 个可迭代的对象,那么 func 必须能接受 N 个参数,而且要并行处理各个可迭代的对象 |
| itertools | starmap(func, it) | 把 it 中的各个元素传给 func,产出结果;输入的可迭代对象应该产出可迭代的元素 iit,然后以 func(*iit) 这种形式调用 func |
# itertools.accumulate
>>> sample = [5, 4, 2, 8, 7, 6, 3, 0, 9, 1]
>>> import itertools
>>> list(itertools.accumulate(sample)) # 计算总和
[5, 9, 11, 19, 26, 32, 35, 35, 44, 45]
>>> list(itertools.accumulate(sample, min)) # 计算最小值
[5, 4, 2, 2, 2, 2, 2, 0, 0, 0]
>>> list(itertools.accumulate(sample, max)) # 计算最大值
[5, 5, 5, 8, 8, 8, 8, 8, 9, 9]
>>> import operator
>>> list(itertools.accumulate(sample, operator.mul)) # 计算乘积
[5, 20, 40, 320, 2240, 13440, 40320, 0, 0, 0]
>>> list(itertools.accumulate(range(1, 11), operator.mul))
[1, 2, 6, 24, 120, 720, 5040, 40320, 362880, 3628800] # 1!-10!
>>> list(enumerate('albatroz', 1)) # 从 1 开始为字母编号
[(1, 'a'), (2, 'l'), (3, 'b'), (4, 'a'), (5, 't'), (6, 'r'), (7, 'o'), (8, 'z')]
>>> import operator
>>> list(map(operator.mul, range(11), range(11))) # 0-10 各数的平方
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
>>> list(map(operator.mul, range(11), [2, 4, 8])) # 对应位置上的两元素乘积
[0, 4, 16]
>>> list(map(lambda a, b: (a, b), range(11), [2, 4, 8])) # 等同于 zip
[(0, 2), (1, 4), (2, 8)]
>>> import itertools
>>> list(itertools.starmap(operator.mul, enumerate('albatroz', 1))) # 从 1 开始,根据字母所在的位置,把字母重复相应的次数
['a', 'll', 'bbb', 'aaaa', 'ttttt', 'rrrrrr', 'ooooooo', 'zzzzzzzz']
>>> sample = [5, 4, 2, 8, 7, 6, 3, 0, 9, 1]
>>> list(itertools.starmap(lambda a, b: b/a,
... enumerate(itertools.accumulate(sample), 1))) # 计算平均值
[5.0, 4.5, 3.6666666666666665, 4.75, 5.2, 5.333333333333333,
5.0, 4.375, 4.888888888888889, 4.5]
14.2.3 合并多个可迭代对象的生成器函数
| 模块 | 函数 | 说明 |
|---|---|---|
| itertools | chain(it1, ..., itN) | 先产出 it1 中的所有元素,然后产出 it2 中的所有元素,以此类推,无缝连接在一起 |
| itertools | chain.from_iterable(it) | 产出 it 生成的各个可迭代对象中的元素,一个接一个,无缝连接在一起;it 应该产出可迭代的元素,例如可迭代的对象列表 |
| itertools | product(it1, ..., itN, repeat=1) | 计算笛卡儿积:从输入的各个可迭代对象中获取元素,合并成由 N 个元素组成的元组,与嵌套的 for 循环效果一样;repeat 指明重复处理多少次输入的可迭代对象 |
| (内置) | zip(it1, ..., itN) | 并行从输入的各个可迭代对象中获取元素,产出由 N 个元素组成的元组,只要有一个可迭代的对象到头了,就默默地停止 |
| itertools | zip_longest(it1, ..., itN, fillvalue=None) | 并行从输入的各个可迭代对象中获取元素,产出由 N 个元素组成的元组,等到最长的可迭代对象到头后才停止,空缺的值使用 fillvalue 填充 |
>>> list(itertools.chain('ABC', range(2)))
['A', 'B', 'C', 0, 1]
>>> list(itertools.chain(enumerate('ABC')))
[(0, 'A'), (1, 'B'), (2, 'C')]
>>> list(itertools.chain.from_iterable(enumerate('ABC')))
[0, 'A', 1, 'B', 2, 'C']
>>> list(zip('ABC', range(5)))
[('A', 0), ('B', 1), ('C', 2)]
>>> list(zip('ABC', range(5), [10, 20, 30, 40]))
[('A', 0, 10), ('B', 1, 20), ('C', 2, 30)]
>>> list(itertools.zip_longest('ABC', range(5)))
[('A', 0), ('B', 1), ('C', 2), (None, 3), (None, 4)]
>>> list(itertools.zip_longest('ABC', range(5), fillvalue='?'))
[('A', 0), ('B', 1), ('C', 2), ('?', 3), ('?', 4)]
# product 笛卡尔积
>>> list(itertools.product('ABC', range(2)))
[('A', 0), ('A', 1), ('B', 0), ('B', 1), ('C', 0), ('C', 1)]
>>> suits = 'spades hearts diamonds clubs'.split()
>>> list(itertools.product('AK', suits))
[('A', 'spades'), ('A', 'hearts'), ('A', 'diamonds'), ('A', 'clubs'),
('K', 'spades'), ('K', 'hearts'), ('K', 'diamonds'), ('K', 'clubs')]
>>> list(itertools.product('ABC'))
[('A',), ('B',), ('C',)]
>>> list(itertools.product('ABC', repeat=2)) # 重复 N 次输入
[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'B'),
('B', 'C'), ('C', 'A'), ('C', 'B'), ('C', 'C')]
>>> list(itertools.product(range(2), repeat=3))
[(0, 0, 0), (0, 0, 1), (0, 1, 0), (0, 1, 1), (1, 0, 0),
(1, 0, 1), (1, 1, 0), (1, 1, 1)]
>>> rows = itertools.product('AB', range(2), repeat=2)
>>> for row in rows: print(row)
...
('A', 0, 'A', 0)
('A', 0, 'A', 1)
('A', 0, 'B', 0)
('A', 0, 'B', 1)
('A', 1, 'A', 0)
('A', 1, 'A', 1)
('A', 1, 'B', 0)
('A', 1, 'B', 1)
('B', 0, 'A', 0)
('B', 0, 'A', 1)
('B', 0, 'B', 0)
('B', 0, 'B', 1)
('B', 1, 'A', 0)
('B', 1, 'A', 1)
('B', 1, 'B', 0)
('B', 1, 'B', 1)
14.2.4 把输入的各个元素扩展成多个输出元素的生成器函数
| 模块 | 函数 | 说明 |
|---|---|---|
| itertools | combinations(it, out_len) | 把 it 产出的 out_len 个元素组合在一起,然后产出 |
| itertools | combinations_with_replacement(it,out_len) | 把 it 产出的 out_len 个元素组合在一起,然后产出,包含相同元素的组合 |
| itertools | count(start=0, step=1) | 从 start 开始不断产出数字,按 step 指定的步幅增加 |
| itertools | cycle(it) | 从 it 中产出各个元素,存储各个元素的副本,然后按顺序重复不断地产出各个元素 |
| itertools | permutations(it, out_len=None) | 把 out_len 个 it 产出的元素排列在一起,然后产出这些排列;out_len 的默认值等于 len(list(it)) |
| itertools | repeat(item, [times]) | 重复不断地产出指定的元素,除非提供 times,指定次数 |
>>> ct = itertools.count()
>>> next(ct)
0
>>> next(ct), next(ct), next(ct)
(1, 2, 3)
>>> list(itertools.islice(itertools.count(1, .3), 3))
[1, 1.3, 1.6]
>>> cy = itertools.cycle('ABC')
>>> next(cy)
'A'
>>> list(itertools.islice(cy, 7))
['B', 'C', 'A', 'B', 'C', 'A', 'B']
>>> rp = itertools.repeat(7)
>>> next(rp), next(rp)
(7, 7)
>>> list(itertools.repeat(8, 4))
[8, 8, 8, 8]
>>> list(map(operator.mul, range(11), itertools.repeat(5)))
[0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50]
>>> list(itertools.combinations('ABC', 2))
[('A', 'B'), ('A', 'C'), ('B', 'C')]
>>> list(itertools.combinations_with_replacement('ABC', 2))
[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'B'), ('B', 'C'), ('C', 'C')]
>>> list(itertools.permutations('ABC', 2))
[('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'C'), ('C', 'A'), ('C', 'B')]
>>> list(itertools.product('ABC', repeat=2))
[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'B'), ('B', 'C'),
('C', 'A'), ('C', 'B'), ('C', 'C')]
14.2.5 用于重新排列元素的生成器函数
| 模块 | 函数 | 说明 |
|---|---|---|
| itertools | groupby(it,key=None) | 产出由两个元素组成的元素,形式为 (key, group),其中 key 是分组标准,group 是生成器,用于产出分组里的元素 |
| (内置) | reversed(seq) | 从后向前,倒序产出 seq 中的元素;seq 必须是序列,或者是实现了 __reversed__ 特殊方法的对象 |
| itertools | tee(it, n=2) | 产出一个由 n 个生成器组成的元组,每个生成器用于单独产出输入的可迭代对象中的元素 |
>>> list(itertools.groupby('LLLLAAGGG'))
[('L', <itertools._grouper object at 0x102227cc0>),
('A', <itertools._grouper object at 0x102227b38>),
('G', <itertools._grouper object at 0x102227b70>)]
>>> for char, group in itertools.groupby('LLLLAAAGG'):
... print(char, '->', list(group))
...
L -> ['L', 'L', 'L', 'L']
A -> ['A', 'A',]
G -> ['G', 'G', 'G']
>>> animals = ['duck', 'eagle', 'rat', 'giraffe', 'bear',
... 'bat', 'dolphin', 'shark', 'lion']
>>> animals.sort(key=len)
>>> animals
['rat', 'bat', 'duck', 'bear', 'lion', 'eagle', 'shark',
'giraffe', 'dolphin']
>>> for length, group in itertools.groupby(animals, len):
... print(length, '->', list(group))
...
3 -> ['rat', 'bat']
4 -> ['duck', 'bear', 'lion']
5 -> ['eagle', 'shark']
7 -> ['giraffe', 'dolphin']
>>> for length, group in itertools.groupby(reversed(animals), len):
... print(length, '->', list(group))
...
7 -> ['dolphin', 'giraffe']
5 -> ['shark', 'eagle']
4 -> ['lion', 'bear', 'duck']
3 -> ['bat', 'rat']
>>> list(itertools.tee('ABC'))
[<itertools._tee object at 0x10222abc8>, <itertools._tee object at 0x10222ac08>]
>>> g1, g2 = itertools.tee('ABC')
>>> next(g1)
'A'
>>> next(g2)
'A'
>>> next(g2)
'B'
>>> list(g1)
['B', 'C']
>>> list(g2)
['C']
>>> list(zip(*itertools.tee('ABC')))
[('A', 'A'), ('B', 'B'), ('C', 'C')]
14.3 深入分析 iter 函数
在 Python 中迭代对象 x 时会调用 iter(x)。可是,iter 函数还有一个鲜为人知的用法:传入两个参数,使用常规的函数或任何可调用的对象创建迭代器。这样使用时,第一个参数必须是可调用的对象,用于不断调用(没有参数),产出各个值;第二个值是哨符,这是个标记值,当可调用的对象返回这个值时,触发迭代器抛出 StopIteration 异常,而不产出哨符。
# 逐行读取文件,直到遇到空行或者到达文件末尾为止
with open('mydata.txt') as fp:
for line in iter(fp.readline, '\n'):
process_line(line)
15 上下文管理器和 else 块
15.1 if 语句之外的 else 块
else 子句不仅能在 if 语句中使用,还能在 for、while 和 try 语句中使用。
else 子句的行为如下。
-
for仅当 for 循环运行完毕时(即 for 循环没有被 break 语句中止)才运行 else 块。 -
while仅当 while 循环因为条件为假值而退出时(即 while 循环没有被 break 语句中止)才运行 else 块。 -
try仅当 try 块中没有异常抛出时才运行 else 块。官方文档还指出:“else 子句抛出的异常不会由前面的 except 子句处理。”
for item in my_list:
if item.flavor == 'banana':
break
else:
raise ValueError('No banana flavor found!')
try:
dangerous_call()
except OSError:
log('OSError...')
else:
after_call()
15.2 上下文管理器和 with 块
上下文管理器对象存在的目的是管理 with 语句,就像迭代器的存在是为了管理 for 语句一样。
with 语句会设置一个临时的上下文,交给上下文管理器对象控制,并且负责清理上下文。这么做能避免错误并减少样板代码,因此 API 更安全,而且更易于使用。
with 语句的目的是简化 try/finally 模式。这种模式用于保证一段代码运行完毕后执行某项操作,即便那段代码由于异常、return 语句或 sys.exit() 调用而中止,也会执行指定的操作。finally 子句中的代码通常用于释放重要的资源,或者还原临时变更的状态。
上下文管理器协议包含 __enter__ 和 __exit__ 两个方法。with 语句开始运行时,会在上下文管理器对象上调用 __enter__ 方法。with 语句运行结束后,会在上下文管理器对象上调用 __exit__ 方法,以此扮演 finally 子句的角色。
@contextmanager 装饰器能减少创建上下文管理器的样板代码量,因为不用编写一个完整的类,定义 __enter__ 和 __exit__ 方法,而只需实现有一个 yield 语句的生成器,生成想让 __enter__ 方法返回的值。
在使用 @contextmanager 装饰的生成器中,yield 语句的作用是把函数的定义体分成两部分:yield 语句前面的所有代码在 with 块开始时(即解释器调用 __enter__ 方法时)执行, yield 语句后面的代码在 with 块结束时(即调用 __exit__ 方法时)执行。
import contextlib
@contextlib.contextmanager
def looking_glass():
import sys
original_write = sys.stdout.write
def reverse_write(text):
original_write(text[::-1])
sys.stdout.write = reverse_write
yield 'JABBERWOCKY'
sys.stdout.write = original_write
>>> from mirror_gen import looking_glass
>>> with looking_glass() as what:
... print('Alice, Kitty and Snowdrop')
... print(what)
...
pordwonS dna yttiK ,ecilA
YKCOWREBBAJ
>>> what
'JABBERWOCKY
16 协程
协程可以处于如下四种状态,当前状态可以使用 inspect.getgeneratorstate(...) 函数确定。
GEN_CREATED等待开始执行。GEN_RUNNING解释器正在执行。GEN_SUSPENDED在 yield 表达式处暂停。GEN_CLOSED执行结束。
>>> def simple_coro2(a):
... print('-> Started: a =', a)
... b = yield a
... print('-> Received: b =', b)
... c = yield a + b
... print('-> Received: c =', c)
...
>>> my_coro2 = simple_coro2(14)
>>> from inspect import getgeneratorstate
>>> getgeneratorstate(my_coro2) # 协程未启动
'GEN_CREATED'
>>> next(my_coro2) # prime 预激协程,让协程向前执行到第一个 yield 表达式,准备好作为活跃的协程使用
-> Started: a = 14 # 向前执行协程到第一个 yield 表达式,打印 -> Started: a = 14 消息
14 # 然后产出 a 的值,并且暂停,等待为 b 赋值
>>> getgeneratorstate(my_coro2) # 在 yield 表达式处暂停
'GEN_SUSPENDED'
>>> my_coro2.send(28) # 把数字 28 发给暂停的协程;b = 28
-> Received: b = 28 # 打印 -> Received: b = 28 消息
42 # 产出 a + b 的值(42),然后协程暂停,等待为 c 赋值。
>>> my_coro2.send(99) # 把数字 99 发给暂停的协程; c = 99
-> Received: c = 99 # 打印 -> Received: c = 99 消息
Traceback (most recent call last): # 协程终止,导致生成器对象抛出 StopIteration 异常
File "<stdin>", line 1, in <module>
StopIteration
>>> getgeneratorstate(my_coro2) # 协程执行结束
'GEN_CLOSED'
simple_coro2 协程的执行过程分为 3 个阶段:
-
调用 next(my_coro2),打印第一个消息,然后执行 yield a,产出数字 14。
-
调用 my_coro2.send(28),把 28 赋值给 b,打印第二个消息,然后执行 yield a + b,产出数字 42。
-
调用 my_coro2.send(99),把 99 赋值给 c,打印第三个消息,协程终止。
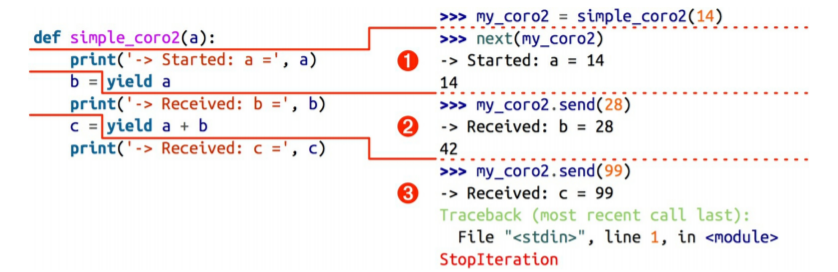
# 使用协程计算移动平均值
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield average
total += term
count += 1
average = total/count
预激活协程:
from functools import wraps
def coroutine(func):
"""装饰器:向前执行到第一个`yield`表达式,预激`func`"""
@wraps(func)
def primer(*args,**kwargs):
gen = func(*args,**kwargs)
next(gen)
return gen
return primer
协程中未处理的异常会向上冒泡,传给 next 函数或 send 方法的调用方(即触发协程的对象)。
class DemoException(Exception):
"""为这次演示定义的异常类型。"""
def demo_finally():
print('-> coroutine started')
try:
while True:
try:
x = yield
except DemoException:
print('*** DemoException handled. Continuing...')
else:
print('-> coroutine received: {!r}'.format(x))
finally:
print('-> coroutine ending')
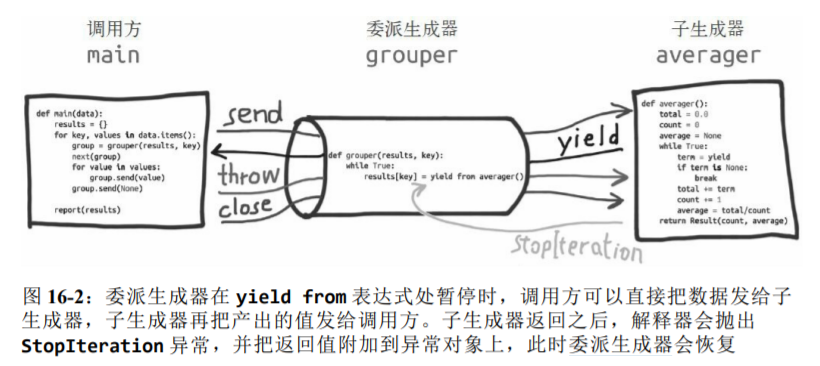
from collections import namedtuple
Result = namedtuple('Result', 'count average')
# 子生成器
def averager():
total = 0.0
count = 0
average = None
while True:
term = yield
if term is None: # 防止 yield from 协程调用堵塞
break
total += term
count += 1
average = total/count
return Result(count, average) # Result 成为 grouper 函数中 yield from 表达式的值
# 委派生成器
def grouper(results, key):
while True: # 每次迭代时会新建一个 averager 实例
results[key] = yield from averager() # 每个实例都是作为协程使用的生成器对象
# yield from x => for _x in x: yield _x
# 客户端代码,即调用方
def main(data):
results = {}
for key, values in data.items():
group = grouper(results, key)
next(group) # 预激 group 协程
for value in values:
group.send(value) # 把各个 value 传给 grouper。传入的值最终到达 averager 函数中 term = yield 那一行;grouper 永远不知道传入的值是什么。
group.send(None) # 重要!把 None 传入 grouper,导致当前的 averager 实例终止,也让 grouper 继续运行,再创建一个 averager 实例,处理下一组值
# print(results) # 如果要调试,去掉注释
report(results)
# 输出报告
def report(results):
for key, result in sorted(results.items()):
group, unit = key.split(';')
print('{:2} {:5} averaging {:.2f}{}'.format(result.count, group, result.average, unit))
data = {
'girls;kg': [40.9, 38.5, 44.3, 42.2, 45.2, 41.7, 44.5, 38.0, 40.6, 44.5],
'girls;m': [1.6, 1.51, 1.4, 1.3, 1.41, 1.39, 1.33, 1.46, 1.45, 1.43],
'boys;kg': [39.0, 40.8, 43.2, 40.8, 43.1, 38.6, 41.4, 40.6, 36.3],
'boys;m': [1.38, 1.5, 1.32, 1.25, 1.37, 1.48, 1.25, 1.49, 1.46],
}
if __name__ == '__main__':
main(data)
$ python3 coroaverager3.py
9 boys averaging 40.42kg
9 boys averaging 1.39m
10 girls averaging 42.04kg
10 girls averaging 1.43m
- 出租车队运营仿真
在一个主循环中处理事件,通过发送数据驱动协程,使用生成器代替线程和回调,实现并发。
事件驱动型框架(如 Tornado 和 asyncio)的运作方式:在单个线程中使用一个主循环驱动协程执行并发活动。使用协程做面向事件编程时,协程会不断把控制权让步给主循环,激活并向前运行其他协程,从而执行各个并发活动。这是一种协作式多任务:协程显式自主地把控制权让步给中央调度程序。而多线程实现的是抢占式多任务。调度程序可以在任何时刻暂停线程(即使在执行一个语句的过程中),把控制权让给其他线程。
import random
import collections
import queue
import argparse
import time
DEFAULT_NUMBER_OF_TAXIS = 3
DEFAULT_END_TIME = 180
SEARCH_DURATION = 5
TRIP_DURATION = 20
DEPARTURE_INTERVAL = 5
Event = collections.namedtuple('Event', 'time proc action')
# BEGIN TAXI_PROCESS
def taxi_process(ident, trips, start_time=0): # <1>
"""Yield to simulator issuing event at each state change"""
time = yield Event(start_time, ident, 'leave garage') # <2>
for i in range(trips): # <3>
time = yield Event(time, ident, 'pick up passenger') # <4>
time = yield Event(time, ident, 'drop off passenger') # <5>
yield Event(time, ident, 'going home') # <6>
# end of taxi process # <7>
# END TAXI_PROCESS
# BEGIN TAXI_SIMULATOR
class Simulator:
def __init__(self, procs_map):
self.events = queue.PriorityQueue()
self.procs = dict(procs_map)
def run(self, end_time, delay=False): # <1>
"""Schedule and display events until time is up"""
# schedule the first event for each cab
for _, proc in sorted(self.procs.items()): # <2>
first_event = next(proc) # <3>
self.events.put(first_event) # <4>
# main loop of the simulation
sim_time = 0 # <5>
while sim_time < end_time: # <6>
if self.events.empty(): # <7>
print('*** end of events ***')
break
# get and display current event
current_event = self.events.get() # <8>
if delay:
time.sleep((current_event.time - sim_time) / 2)
# update the simulation time
sim_time, proc_id, previous_action = current_event
print('taxi:', proc_id, proc_id * ' ', current_event)
active_proc = self.procs[proc_id]
# schedule next action for current proc
next_time = sim_time + compute_duration(previous_action)
try:
next_event = active_proc.send(next_time) # <12>
except StopIteration:
del self.procs[proc_id] # <13>
else:
self.events.put(next_event) # <14>
else: # <15>
msg = '*** end of simulation time: {} events pending ***'
print(msg.format(self.events.qsize()))
# END TAXI_SIMULATOR
def compute_duration(previous_action):
"""Compute action duration using exponential distribution"""
if previous_action in ['leave garage', 'drop off passenger']:
# new state is prowling
interval = SEARCH_DURATION
elif previous_action == 'pick up passenger':
# new state is trip
interval = TRIP_DURATION
elif previous_action == 'going home':
interval = 1
else:
raise ValueError('Unknown previous_action: %s' % previous_action)
return int(random.expovariate(1/interval)) + 1
def main(end_time=DEFAULT_END_TIME, num_taxis=DEFAULT_NUMBER_OF_TAXIS,
seed=None, delay=False):
"""Initialize random generator, build procs and run simulation"""
if seed is not None:
random.seed(seed) # get reproducible results
taxis = {i: taxi_process(i, (i+1)*2, i*DEPARTURE_INTERVAL)
for i in range(num_taxis)}
sim = Simulator(taxis)
sim.run(end_time, delay)
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description='Taxi fleet simulator.')
parser.add_argument('-e', '--end-time', type=int,
default=DEFAULT_END_TIME,
help='simulation end time; default = %s'
% DEFAULT_END_TIME)
parser.add_argument('-t', '--taxis', type=int,
default=DEFAULT_NUMBER_OF_TAXIS,
help='number of taxis running; default = %s'
% DEFAULT_NUMBER_OF_TAXIS)
parser.add_argument('-s', '--seed', type=int, default=None,
help='random generator seed (for testing)')
parser.add_argument('-d', '--delay', action='store_true',
help='introduce delay proportional to simulation time')
args = parser.parse_args()
main(args.end_time, args.taxis, args.seed, args.delay)
17 使用期物处理并发
concurrent.futures 模块的主要特色是 ThreadPoolExecutor 和 ProcessPoolExecutor 类,这两个类实现的接口能分别在不同的线程或进程中执行可调用的对象。这两个类在内部维护着一个工作线程或进程池,以及要执行的任务队列。
def download_many(cc_list):
workers = min(MAX_WORKERS, len(cc_list)) # 设定工作的线程数量
with futures.ThreadPoolExecutor(workers) as executor: # 使用工作的线程数实例化 ThreadPoolExecutor 类
res = executor.map(download_one, sorted(cc_list)) # map 方法返回一个生成器,因此可以迭代,获取各个函数返回的值
return len(list(res)) # 返回获取的结果数量;如果有线程抛出异常,异常会在这里抛出,这与隐式调用 next() 函数从迭代器中获取相应的返回值一样
期物封装待完成的操作,可以放入队列,完成的状态可以查询,得到结果(或抛出异常)后可以获取结果(或异常)。
CPython 解释器本身就不是线程安全的,因此有全局解释器锁(GIL, Global Interpreter Lock),一次只允许使用一个线程执行 Python 字节码。因此,一个 Python 进程通常不能同时使用多个 CPU 核心。Python 标准库中的所有阻塞型 I/O 函数都会释放 GIL,允许其他线程运行。time.sleep() 函数也会释放 GIL。因此,尽管有 GIL,Python 线程还是能在 I/O 密集型应用中发挥作用。
concurrent.futures 模块实现了真正的并行运算,通过 ProcessPoolExecutor 类把工作分配给多个 Python 进程处理。因此,如果需要做 CPU 密集型处理,使用这个模块能绕开 GIL,利用所有可用的 CPU 核心。
Executor.map 函数易于使用,返回结果的顺序与开始调用的顺序一致,如果第一个调用生成结果用时 10 秒,而其他调用只用 1 秒,代码会阻塞 10 秒,获取 map 方法返回的生成器产出的第一个结果。
executor.submit 和 futures.as_completed 这个组合比 executor.map 更灵活,因为 submit 方法能处理不同的可调用对象和参数,而 executor.map 只能处理参数不同的同一个可调用对象。此外,传给 futures.as_completed 函数的期物集合可以来自多个 Executor 实例,例如一些由 ThreadPoolExecutor 实例创建,另一些由 ProcessPoolExecutor 实例创建。
def download_many(cc_list, base_url, verbose, concur_req):
counter = collections.Counter()
with futures.ThreadPoolExecutor(max_workers=concur_req) as executor: # max_workers = min(len(cc_list), concur_req, MAX_CONCUR_REQ)
to_do_map = {} # Future => 国家代码
for cc in sorted(cc_list): # 按字母顺序迭代国家代码列表
future = executor.submit(download_one,
cc, base_url, verbose) # 排定可调用对象的执行时间,返回 Future 实例
to_do_map[future] = cc # future => 国家代码
done_iter = futures.as_completed(to_do_map) # 返回一个迭代器,在期物运行结束后产出期物。
if not verbose:
done_iter = tqdm.tqdm(done_iter, total=len(cc_list)) # 非详尽模式显示进度条,done_iter 无 len 函数指定 total 参数
for future in done_iter: # 迭代运行结束后的期物
try:
res = future.result() # 获取返回值
except requests.exceptions.HTTPError as exc: # 处理可能出现的异常
error_msg = 'HTTP {res.status_code} - {res.reason}'
error_msg = error_msg.format(res=exc.response)
except requests.exceptions.ConnectionError as exc:
error_msg = 'Connection error'
else:
error_msg = ''
status = res.status
if error_msg:
status = HTTPStatus.error
counter[status] += 1
if verbose and error_msg:
cc = to_do_map[future] # <16>
print('*** Error for {}: {}'.format(cc, error_msg))
return counter
把期物存储在一个字典中,提交期物时把期物与相关的信息联系起来;这样,as_completed 迭代器产出期物后,就可以使用那些信息。
对 CPU 密集型工作来说,要启动多个进程,规避 GIL。创建多个进程最简单的方式是,使用 futures.ProcessPoolExecutor 类。不过和前面一样,如果使用场景较复杂,需要更高级的工具。multiprocessing 模块 的 API 与 threading 模块相仿,不过作业交给多个进程处理。对简单的程序来说,可以用 multiprocessing 模块代替 threading 模块,少量改动即可。不过 multiprocessing 模块还能解决协作进程遇到的最大挑战:在进程之间传递数据。
18 使用 asyncio 包处理并发
并发是指一次处理多件事。并行是指一次做多件事。一个关于结构,一个关于执行。并发用于制定方案,用来解决可能(但未必)并行的问题。
asyncio 包,使用事件循环驱动的协程实现并发。使用协程解决回调的主要问题:执行分成多步的异步任务时丢失上下文,以及缺少处理错误所需的上下文。
异步库依赖于低层线程(直至内核级线程),但是这些库的用户无需创建线程,也无需知道用到了基础设施中的低层线程。在应用中,我们只需确保没有阻塞的代码,事件循环会在背后处理并发。异步系统能避免用户级线程的开销,这是它能比多线程系统管理更多并发连接的主要原因。
import asyncio
import collections
import aiohttp
from aiohttp import web
import tqdm
from flags2_common import main, HTTPStatus, Result, save_flag
# default set low to avoid errors from remote site, such as
# 503 - Service Temporarily Unavailable
DEFAULT_CONCUR_REQ = 5
MAX_CONCUR_REQ = 1000
class FetchError(Exception):
def __init__(self, country_code):
self.country_code = country_code
# BEGIN FLAGS3_ASYNCIO
@asyncio.coroutine
def http_get(url):
res = yield from aiohttp.request('GET', url)
if res.status == 200:
ctype = res.headers.get('Content-type', '').lower()
if 'json' in ctype or url.endswith('json'):
data = yield from res.json() # <1>
else:
data = yield from res.read() # <2>
return data
elif res.status == 404:
raise web.HTTPNotFound()
else:
raise aiohttp.errors.HttpProcessingError(
code=res.status, message=res.reason,
headers=res.headers)
@asyncio.coroutine
def get_country(base_url, cc):
url = '{}/{cc}/metadata.json'.format(base_url, cc=cc.lower())
metadata = yield from http_get(url) # <3>
return metadata['country']
@asyncio.coroutine
def get_flag(base_url, cc):
url = '{}/{cc}/{cc}.gif'.format(base_url, cc=cc.lower())
return (yield from http_get(url)) # <4>
@asyncio.coroutine
def download_one(cc, base_url, semaphore, verbose):
try:
with (yield from semaphore): # <5>
image = yield from get_flag(base_url, cc)
with (yield from semaphore):
country = yield from get_country(base_url, cc)
except web.HTTPNotFound:
status = HTTPStatus.not_found
msg = 'not found'
except Exception as exc:
raise FetchError(cc) from exc
else:
country = country.replace(' ', '_')
filename = '{}-{}.gif'.format(country, cc)
loop = asyncio.get_event_loop()
loop.run_in_executor(None, save_flag, image, filename) # 把阻塞的作业委托给线程池做
status = HTTPStatus.ok
msg = 'OK'
if verbose and msg:
print(cc, msg)
return Result(status, cc)
# END FLAGS3_ASYNCIO
@asyncio.coroutine
def downloader_coro(cc_list, base_url, verbose, concur_req):
counter = collections.Counter()
semaphore = asyncio.Semaphore(concur_req)
to_do = [download_one(cc, base_url, semaphore, verbose)
for cc in sorted(cc_list)]
to_do_iter = asyncio.as_completed(to_do) # 获取一个迭代器,这个迭代器会在期物运行结束后返回期物
if not verbose:
to_do_iter = tqdm.tqdm(to_do_iter, total=len(cc_list))
for future in to_do_iter:
try:
res = yield from future
except FetchError as exc:
country_code = exc.country_code
try:
error_msg = exc.__cause__.args[0]
except IndexError:
error_msg = exc.__cause__.__class__.__name__
if verbose and error_msg:
msg = '*** Error for {}: {}'
print(msg.format(country_code, error_msg))
status = HTTPStatus.error
else:
status = res.status
counter[status] += 1
return counter
def download_many(cc_list, base_url, verbose, concur_req):
loop = asyncio.get_event_loop()
coro = downloader_coro(cc_list, base_url, verbose, concur_req) # 实例化 downloader_coro 协程
counts = loop.run_until_complete(coro)
loop.close()
return counts
if __name__ == '__main__':
main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ)